캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (1)

오랫만에 데이터 분석 실습 포스트를 진행 합니다.
데이터 분석은 저도 아직.. 많이 허접한 실력을 가지고 있기 때문에, 이 글을 보시는 많은 실력자 분들께서 조언을 해주시면 감사 할 것 같습니다. 그리고 저처럼 하나씩 배워 가시는 분들 또한 같이 여기서 실력을 키워 갔으면 좋겠습니다.
데이터 소스 알아보기
이번에 데이터 분석을 진행 할 대상 데이터는 넷플릭스 데이터 입니다.
아래 그림과 같이 데이터에 대한 개요와 생김새 등을 알수 있습니다.

넷플릭스에 등록되어 있는 각종 영상 및 영화, 드라마등 각 프로그램별 제목, 감독, 배우 등등의 정보가 2019년 기준으로 저장이 되어 있는것을 확인 할 수 있습니다. 엑셀로 데이터를 뽑아보니 아래와 같이 정보들이 들어가 있는 것을 확인 할 수 있었습니다.
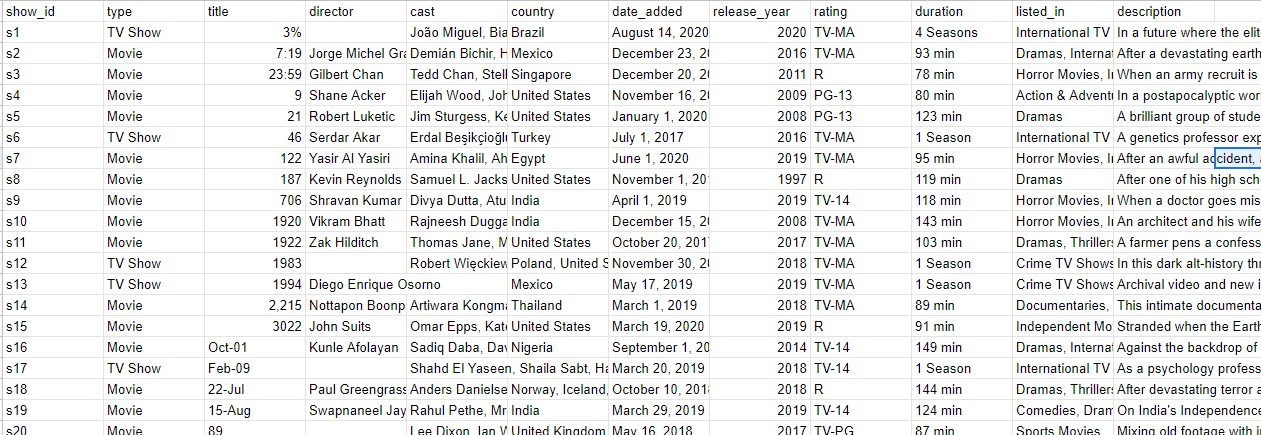
데이터는 제가 여기에 올려 드리도록 하겠습니다.
아래 데이터를 다운로드 하셔서 실습을 따라 해보셔도 좋겠습니다.
따로 경로를 알고 싶으신 분들은 아래 경로로 가셔서 다운로드 받으시면 됩니다.
www.kaggle.com/shivamb/netflix-shows
Netflix Movies and TV Shows
Movies and TV Shows listings on Netflix
www.kaggle.com
데이터 분석 실습 코드
자, 우선 데이터 분석에 필요한 라이브러리들을 import 합니다. 그리고, 데이터도 함께 pandas에 저장을 합니다.
코드는 다음과 같습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
import plotly.express as px
import plotly.graph_objects as go
import warnings
warnings.filterwarnings("ignore")
#data import
main_df=pd.read_csv("D:/jscode/python_basic/netflix_titles.csv")
print(main_df.head())아래와 같이 데이터를 넣은 main_df의 내용을 미리 볼 수 있습니다.

여기서, 또 각 데이터 컬럼들의 정보도 한번 살펴 볼께요.
#data columns info
print(main_df.info())결과는 아래와 같이 나옵니다.

각 컬럼들의 description은 아래와 같으니 참고 하시기 바랍니다. 캐글에서 가지고 왔어요~!
|
다음은 결측치 분포도를 확인 해보겠습니다.
데이터 분석에서는 결측치가 매우 중요 합니다. 결측치란, 데이터셋에서 빈값이 존재하는것을 이야기 합니다. 빈 값이 얼마나 어디에 있는지를 확인 하는 절차 입니다.
코드를 보겠습니다.
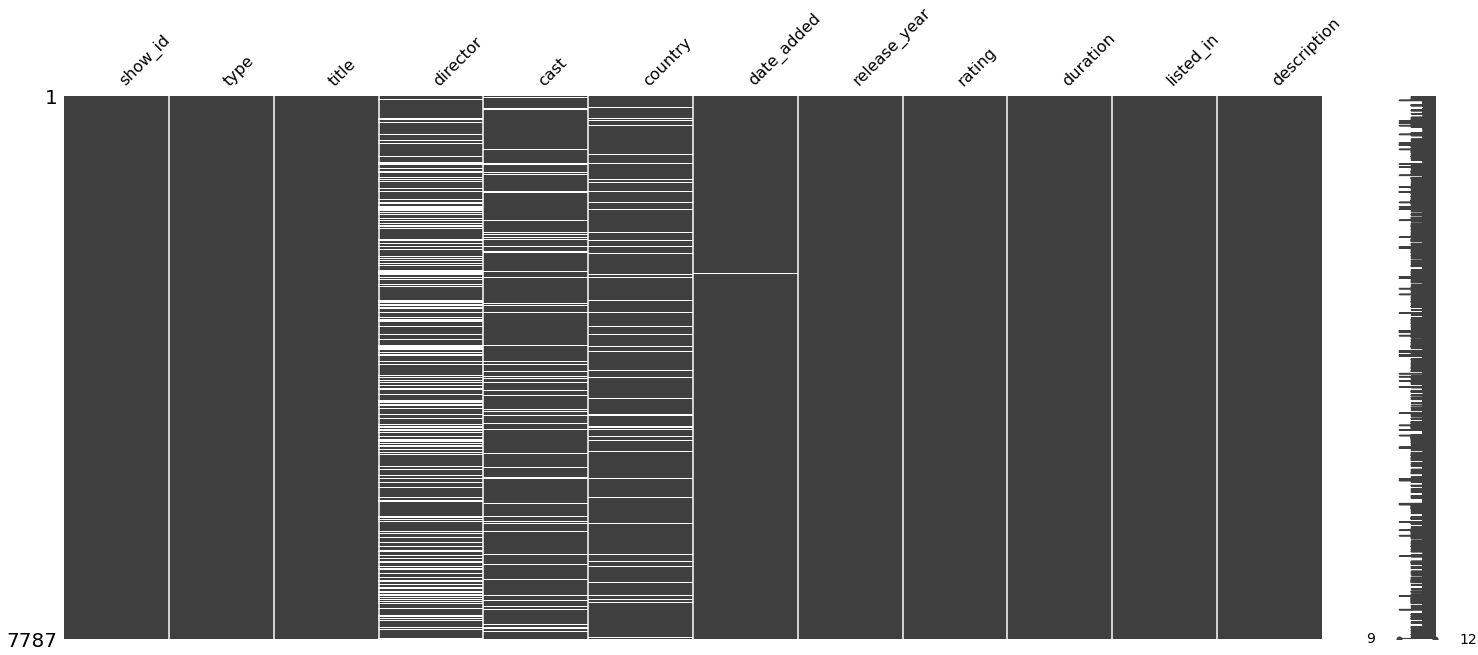
# 데이터 결측치 분포도
msno.matrix(main_df)아래와 같은 그림이 짠! 여기서 흰색 부분이 데이터가 비어있는 부분이라고 생각 하시면 됩니다.
director와 cast, country 부분에 빈 데이터가 많이 눈에 띄입니다.
결측치를 위에서는 이미지로 확인 했지만, 숫자로 한번 확인 해보겠습니다.
# 결측치 차트
msno.bar(main_df);결과는 아래와 같습니다.

총 7787건인데, 각 컬럼별로 그 숫자가 안되면 비어 있는것이 있다는 의미겠죠?
director, cast, country, date_added, rating 에서 빈 값들이 있다는 것을 확인 할 수 있습니다.
이번엔 각 컬럼별 결측치에 대한 비율을 rate로 확인 해보도록 하겠습니다.
소스 코드는 다음과 같습니다.
for i in main_df.columns:
null_rate = main_df[i].isna().sum() / len(main_df) * 100
if null_rate > 0 :
print("{}'s null rate :{}%".format(i,round(null_rate,2)))위 코드를 실행하면 아래와 같은 결과가 출력이 됩니다.

우리가 그동안 그래프로 보아왔던 결과와 같이 director의 결측 데이터가 많은것을 rate도로 확인 할 수 있습니다.
이번에는 결측치는 아니고, 유닉크한 데이터 수를 뽑아내는 코드를 작성 하겠습니다. nunique() 함수를 사용하여 간단하게 아래와 같이 결과를 볼 수 있습니다.
main_df.nunique()결과를 볼께요!

여기 나오는 숫자는 각 컬럼별 데이터에서 데이터를 group by 하였을때의 카운트 입니다. 즉, 어떤 컬럼의 데이터가 모두 유니크하다면 전체 데이터 수인 7787개가 나오게 되겠죠? 결과가 7787개인 컬럼은 show_id와 title뿐이네요. 이 두 컬럼의 데이터는 유니크한것을 알 수 있습니다.
마지막으로 결측데이터의 수를 뽑아 보도록 하겠습니다.
코드는 다음과 같습니다.
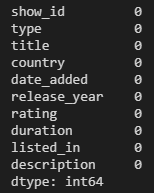
main_df.isna().sum()결과는 아래와 같이 나왔습니다.

main_df.isna().sum()
결측치 보정
자, 이번엔 결측치에 대한 보정을 합니다. 결측 데이터를 기반으로 하나씩 결측치 보정을 합니다.
가장 먼저 위에서 조사한 바에 따라 rating 이라는 컬럼을 보정하겠습니다. 전체 유니크한 값을 14개 인데, 빈 데이터가 7개 뿐입니다. 어떤 show에 대한 등급을 나타내는 데이터네요.

위 그림처럼 7개 rating 컬럼에 값이 비어 있는데, 채워 주겠습니다.
rating_replacements = {
67: 'TV-PG',
2359: 'TV-14',
3660: 'TV-MA',
3736: 'TV-MA',
3737: 'NR',
3738: 'TV-MA',
4323: 'TV-MA '
}
for id, rate in rating_replacements.items():
main_df.iloc[id, 8] = rate
main_df['rating'].isna().sum()각 행 별로 rating 값을 replace 합니다. 마지막 행에서 다시 비어있는것을 출력하라고 했더니 이젠 나오지 않는것을 확인 할 수 있습니다.
그리고 결측치가 많은 director와 cast 컬럼은 drop 하도록 하겠습니다.
main_df = main_df.drop(['director', 'cast'], axis=1)
main_df.columns
아래 그림과 같이 column들이 drop 된 것을 확인 할 수 있습니다.

다음은 컬럼값을 채우기 힘든 date_added 컬럼에 대해서 빈 데이터가 있는 rows를 삭제 합니다.
main_df=main_df[main_df["date_added"].notna()]그리고 다시 잘 삭제가 되었는지 확인을 아래 명령어로 해볼께요. 위에서 했던 빈 값을 세는 명령이죠.
main_df.isna().sum()결과가 아래와 같이 잘 나옵니다.
우리가 지운 데이터, 컬럼을 삭제 한 데이터, 새롭게 채운 데이터가 잘 들어 간 것을 확인 할 수 있습니다.

마지막으로는 country 컬럼의 결측치를 채워 보겠습니다. 총 506개의 결측치가 있습니다.
가장 많이 있는 값으로 채우겠습니다.
코드는 아래와 같습니다.
main_df['country'] = main_df['country'].fillna(main_df['country'].mode()[0])이젠 결측치가 없겠죠? 아래 코드로 확인 해보겠습니다.
main_df.isna().sum()아래와 같이 결측치가 없는것을 확인 합니다.
데이터 클랜징 확인
이번 포스트 마무리
자, 오늘은 데이터를 확인하고 결측치를 확인 하고, 결측치를 채우는 것까지 실습을 해봤습니다.
본격적인 내용은 다음 포스트에 이어서 진행을 하도록 하겠습니다.
감사합니다.
## 다음편 보러가기 ##
2021/03/03 - [Data Science] - 캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (2)
캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (2)
캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (2) 안녕하세요. 지난번 넷플릭스 데이터를 이용한 데이터 분석 실습 1편에 이어서 2편을 작성 합니다. 지난 1편을 보시고 싶으신 분들은
stricky.tistory.com
## 캐클 타이타닉 데이터 분석 바로가기 ##
2019/12/26 - [DB엔지니어가 공부하는 python] - [python 데이터분석] 캐글 타이타닉 따라해보기 #1
[python 데이터분석] 캐글 타이타닉 따라해보기 #1
오늘부터는 캐글에서 진행했던 데이터 분석 대회 중 하나인 타이타닉을 따라 해 볼 거다. 아직 난 파린이닌깐... # 대회 링크는 : https://www.kaggle.com/c/2019-1st-ml-month-with-kakr/data 위 링크에 들어가..
stricky.tistory.com
2019/12/26 - [DB엔지니어가 공부하는 python] - [python 데이터분석] 캐글 타이타닉 따라해보기 #2
[python 데이터분석] 캐글 타이타닉 따라해보기 #2
# 캐글 타이타닉 따라해보기 2탄 입니다. 아마 타이타닉 따라하기는 마지막 편이 될 것 같습니다. 전편 보기 : 2019/12/26 - [DB엔지니어가 공부하는 python] - [python] 캐글 타이타닉 따라해보기 #1 [python]
stricky.tistory.com
by.sTricky
'Data Science' 카테고리의 다른 글
| 캐글 데이터 시각화 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (3) (0) | 2021.03.09 |
|---|---|
| 캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (2) (0) | 2021.03.03 |
| Rain in Australia 캐글 날씨 데이터셋 다운로드 받아 mysql에 넣는 방법 (0) | 2021.02.17 |
| Softmax Regression 기본 개념 파악 및 실습하기 | sTricky (0) | 2021.02.07 |
| Logistic classification 모두의 딥러닝 실습 및 개념 파악 하기 | sTricky (0) | 2021.01.31 |



