# 캐글 타이타닉 따라해보기 2탄 입니다.
아마 타이타닉 따라하기는 마지막 편이 될 것 같습니다.
전편 보기 :
2019/12/26 - [DB엔지니어가 공부하는 python] - [python] 캐글 타이타닉 따라해보기 #1
[python] 캐글 타이타닉 따라해보기 #1
오늘 부터는 캐글에서 진행했던 데이터 분석 대회중 하나인 타이타닉을 따라해볼꺼다. 아직 난 파린이닌깐... # 대회 링크는 : https://www.kaggle.com/c/2019-1st-ml-month-with-kakr/data 위 링크에 들어가서 데..
stricky.tistory.com
전편에도 제가 언급했지만, 캐글 타이타닉 따라해보기는 아래 참조 블로그가 있습니다.
참조 블로그 :
https://cyc1am3n.github.io/2018/10/09/my-first-kaggle-competition_titanic.html
캐글 타이타닉 생존자 예측 도전기 (1)
이번에는 캐글의 입문자를 위한 튜토리얼 문제라고 할 수 있는 Titanic: Machine Learning from Disaster 의 예측 모델을 python으로 풀어보는 과정에 대해서 포스트를 할 것이다.
cyc1am3n.github.io
이거 보고 거의.... 따라한다 생각하면 됩니다.
중간 중간 오탈자 수정 및, 제 생각 얹기 정도? 그것도 사실 많지 않습니다만..
암튼,, 따라서 시작 하겠습니다.
전편에서 pie chart 와 bar chart 그려서 데이터의 분포를 확인 하는것 까지 했습니다.
이젠 데이터를 파이썬이 학습 할 수 있도록 전처리 하는 과정을 해볼께요~
우선 전처리를 시작 하기 전에 train 데이터와 test 데이터를 합치겠습니다.
이는, 두 데이터를 한꺼번에 전처리 하기 위함 입니다.
train_and_test = [train, test]이젠, 데이터 처리를 하는데,
데이터의 영문 이름을 보면 흔히 miss, mr 등등의 수식어가 붙습니다.
이 데이터를 잘라 내어 따로 컬럼을 만들 겠습니다.
for dataset in train_and_test:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.')
train.head()정규식 표현도 들어가 있네요, 공백으로 시작하여 "."으로 끝나는 데이터를 이름에서 잘라 내었습니다.
이 데이터를 가지고 성별과 함께 표시 해 보겠습니다.
pd.crosstab(train['Title'], train['Sex'])그럼 이런 데이터가 나옵니다..
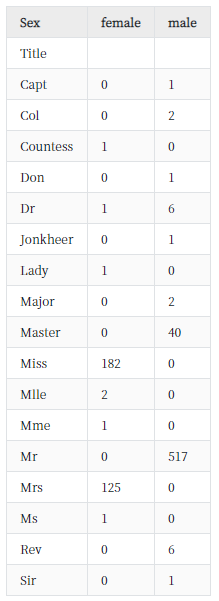
여기에서 잘 쓰이지 않는 수식어 title을 "Other"로 대체하고, Mlle, Mme, Ms등도 유연한 표현으로 바꾸어 줍니다.
그리고나서 각 title별 생존률을 한번 뽑아 보겠습니다.
for dataset in train_and_test:
dataset['Title'] = dataset['Title'].replace(['Capt', 'Col', 'Countess', 'Don','Dona', 'Dr', 'Jonkheer',
'Lady','Major', 'Rev', 'Sir'], 'Other')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()위 코드의 결과는 아래와 같습니다.

다음은 title, sex 데이터를 학습을 할 수 있도록 String Data Type으로 변형 해줍니다.
for dataset in train_and_test:
dataset['Title'] = dataset['Title'].astype(str)
for dataset in train_and_test:
dataset['Sex'] = dataset['Sex'].astype(str)다음은, Embarked (탑승항구) 데이터에 대해서 String Data Type으로 변형할껀데, 앞서
해당 데이터를 들여다 보니 NaN값이 있습니다. 해당 데이터의 분포를 먼저 살펴 보겠습니다.
train.Embarked.value_counts(dropna=False)
#참고 블로그에 오탈자가 있어 위와 같이 수정 합니다.
#원문 : train.Embared.value_count(dropna=False)S 644
C 168
Q 77
NaN 2
Name: Embarked, dtype: int64
위와 같은 데이터 분포를 가지는데 NaN값을 가진 두건에 대해서는 대부분의 데이터를 차지하는 "S" 값으로 대체 하겠습니다.
그리고 String Data Type으로 변형 합니다.
for dataset in train_and_test:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
dataset['Embarked'] = dataset['Embarked'].astype(str)Age 데이터에도 NaN값이 존재 하는데, 여기에는 나머지 모든 승객의 평균 Age를 넣어줍니다.
그리고 Age 데이터는 Binning 기법을 사용하여 Age를 5개의 구간으로 나눠 생존률을 예측해 보겠다.
Binning 이란 연속성 있는 데이터를 구간으로 나누어 범주화 하는 방법을 지칭한다.
여기서 Age 데이터를 16살의 간격으로 나누어, 해당 구간을 string 형식의 명칭을 사용 하여 분리 시켜 보았다.
for dataset in train_and_test:
dataset['Age'].fillna(dataset['Age'].mean(), inplace=True)
dataset['Age'] = dataset['Age'].astype(int)
train['AgeBand'] = pd.cut(train['Age'], 5)
print (train[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean()) # Survivied ratio about Age Band
for dataset in train_and_test:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
dataset['Age'] = dataset['Age'].map( { 0: 'Child', 1: 'Young', 2: 'Middle', 3: 'Prime', 4: 'Old'} ).astype(str)여기서 참고 블로그의 저자는 숫자에 대한 경향성을 가지고 싶지 않아서 각 그룹의 명칭을 string type으로 했다고 했는데.. 무슨 말인지 잘 이해는 되지 않는다.. 나중에 내공이 쌓이면 이해가 되겠지..ㅎㅎ
그리고 Test 데이터에서 보면 Fare에도 NaN값이 있는 이는 운임비용으로 당연히 Pclass (티켓 등급)과 관련이 있을것 이기에, 빠지 NaN 데이터에는 해당 Pclass를 가진 사람들의 평균값을 Fare로 채워 넣어주는 작업을 한다.
print (train[['Pclass', 'Fare']].groupby(['Pclass'], as_index=False).mean())
print("")
print(test[test["Fare"].isnull()]["Pclass"])결과는 아래와 같다.
Pclass Fare
0 1 84.154687
1 2 20.662183
2 3 13.675550
152 3
Name: Pclass, dtype: int64
NaN 데이터에 아래와 같이 값을 채워주자..
for dataset in train_and_test:
dataset['Fare'] = dataset['Fare'].fillna(13.675) # The only one empty fare data's pclass is 3.아까 Age에서도 그랬듯이, Fare (운임비용)에서도 Binning을 한다. 하지만 위에서와는 달리 Numeric한 값으로 남겨둔다.
for dataset in train_and_test:
dataset.loc[ dataset['Fare'] <= 7.854, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.854) & (dataset['Fare'] <= 10.5), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 10.5) & (dataset['Fare'] <= 21.679), 'Fare'] = 2
dataset.loc[(dataset['Fare'] > 21.679) & (dataset['Fare'] <= 39.688), 'Fare'] = 3
dataset.loc[ dataset['Fare'] > 39.688, 'Fare'] = 4
dataset['Fare'] = dataset['Fare'].astype(int)1편의 마지막에서 말했듯이 누군가(형제, 자매, 배우자, 부모님, 자녀)와 함께 탑승한 승객의 생존률은 높았는데, 이 두 데이터를 합쳐서 Family라는 Feature로 만들어 보자. 그리고 해당 데이터는 int type으로 변환한다.
for dataset in train_and_test:
dataset["Family"] = dataset["Parch"] + dataset["SibSp"]
dataset['Family'] = dataset['Family'].astype(int)
이젠, 계획했던 Feature Data의 전처리가 끝났으니, 학습 시킬때 제외 시킬 Feature들을 Drop 하자..
features_drop = ['Name', 'Ticket', 'Cabin', 'SibSp', 'Parch']
train = train.drop(features_drop, axis=1)
test = test.drop(features_drop, axis=1)
train = train.drop(['PassengerId', 'AgeBand'], axis=1)
print(train.head())
print(test.head())
#참고 블로그에 오탈자가 있어 위와 같이 수정 합니다.
#원본 블로그 : train = train.drop(['PassengerId', 'AgeBand', 'FareBand'], axis=1)
#FareBand는 원본 블로그 내에서는 언급 된적 없는 feature 입니다.위 코드의 실행 결과는 아래와 같다.
Survived Pclass Sex Age Fare Embarked Title Family
0 0 3 male Young 0 S Mr 1
1 1 1 female Middle 4 C Mrs 1
2 1 3 female Young 1 S Miss 0
3 1 1 female Middle 4 S Mrs 1
4 0 3 male Middle 1 S Mr 0
PassengerId Pclass Sex Age Fare Embarked Title Family
0 892 3 male Middle 0 Q Mr 0
1 893 3 female Middle 0 S Mrs 1
2 894 2 male Prime 1 Q Mr 0
3 895 3 male Young 1 S Mr 0
4 896 3 female Young 2 S Mrs 2
자, 이렇게 마지막으로 가공된 train, test 데이터를 볼 수 있다.
이것들을 Categorical Feature에 대해 one-hot encoding과 train data와 label을 분리시키는 작업을 하면 예측 모델에 학습시킬 준비가 끝났다.
(사실 무슨 말인지 아직 정확하게 모르겠다.. 좀 더 공부가 필요하다..)
# One-hot-encoding for categorical variables
train = pd.get_dummies(train)
test = pd.get_dummies(test)
train_label = train['Survived']
train_data = train.drop('Survived', axis=1)
test_data = test.drop("PassengerId", axis=1).copy()
자, 마지막 단계이다. 학습을 통해서 결과를 얻어 내어야 한다.
이번 작업에서 예측 모델로 사용할 것은 아래와 같이 5가지 이다.
- Logistic Regression
- Support Vector Machine (SVM)
- k-Nearest Neighbor (kNN)
- Random Forest
- Naive Bayes
원작자님께서는 자세한 설명을 포스팅 한다고 하셨다..
실제 했는지, 안했는지 안찾아봤는데.. 아직 안한것 같다.
따로 찾아보자..ㅎㅎ
일단 위 모델을 사용하기 위해 라이브러리를 import 한다.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.utils import shuffle그리고, 데이터가 정렬되어 있어 학습에 방해가 생길지 모르니 데이터를 섞어준다고 했다..
왜??? 글쎄..ㅎㅎ
이것도 학습을 하다보면 알게 되지 않을까?
train_data, train_label = shuffle(train_data, train_label, random_state = 5)이제 모델 학습과 평가에 대한 pipeline을 만들자.
사실 scikit-learn에서 제공하는 fit()과 predict()를 사용하면 매우 간단하게 학습과 예측을 할 수 있어서 그냥 하나의 함수만 만들면 편하게 사용가능하다.
def train_and_test(model):
model.fit(train_data, train_label)
prediction = model.predict(test_data)
accuracy = round(model.score(train_data, train_label) * 100, 2)
print("Accuracy : ", accuracy, "%")
return prediction이젠 위에서 언급한 5가지 학습 모델을 이용해서 학습과 평가를 해보자..
# Logistic Regression
log_pred = train_and_test(LogisticRegression())
# SVM
svm_pred = train_and_test(SVC())
#kNN
knn_pred_4 = train_and_test(KNeighborsClassifier(n_neighbors = 4))
# Random Forest
rf_pred = train_and_test(RandomForestClassifier(n_estimators=100))
# Navie Bayes
nb_pred = train_and_test(GaussianNB())Accuracy : 82.72 %
Accuracy : 83.5 %
Accuracy : 85.41 %
Accuracy : 88.55 %
Accuracy : 79.8 %
아웃풋은 위와 같다.
여기서 4번째 모델의 정확도가 가장 높았으니 (88.55%)
이 모델을 이용해서 submission 해본다.
submission = pd.DataFrame({
"PassengerId": test["PassengerId"],
"Survived": rf_pred
})
submission.to_csv('E:/kaggle_korea/2019-1st-ml-month-with-kakr/submission_rf.csv', index=False)참조 블로그의 원작자는 이것을 캐글에 결과를 올렸더니 만명중에 5천등정도로 나왔다고 한다.
그리고, 개선점으로는
1. Data에 있는 Outlier 제거하기
2. 데이터 분석을 더 자세하게 하기
3. NaN 값을 다른 방법으로 채워넣기
4. 사용하지 않은 Feature(Ticket, Cabin) 활용하기
5. 모델 설계, hyperparameter 선택, 평가(Cross Validation)를 직접 구현해서 진행하기이렇게 꼽아주었다.
이젠 우리가 한번 개선 해보자.
허접한 따라하기를 봐주신 여러분들께 마지막으로 감사드리며,
원작 블로그 작성자님께서 감사를 드립니다.
열심히 해볼께요!
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| [python] 인터넷이 안되는곳에서 파이썬 패키지 설치하기! (pip download) (2) | 2020.01.03 |
|---|---|
| [python] 텍스트 파일에서 명사만 뽑아서 명사별 빈도 카운트 하기 konlypy (0) | 2019.12.30 |
| [python 데이터분석] 캐글 타이타닉 따라해보기 #1 (0) | 2019.12.26 |
| [python] 기본이 되는 numpy (0) | 2019.12.26 |
| [python] 크롤러 만들어 db에 정보 insert 하기 (3) | 2019.12.24 |



