오늘부터는 캐글에서 진행했던 데이터 분석 대회 중 하나인 타이타닉을 따라 해 볼 거다.
아직 난 파린이닌깐...
# 대회 링크는 : https://www.kaggle.com/c/2019-1st-ml-month-with-kakr/data
위 링크에 들어가서 데이터 셋도 한번 살펴보고.. 대회 요강 등도 한번 살펴보자..
그리고 나는,
괜찮은 튜토리얼 블로그를 하나 보고 따라 할 생각이다.
그래서 찾은 블로그는...
https://cyc1am3n.github.io/2018/10/09/my-first-kaggle-competition_titanic.html
캐글 타이타닉 생존자 예측 도전기 (1)
이번에는 캐글의 입문자를 위한 튜토리얼 문제라고 할 수 있는 Titanic: Machine Learning from Disaster 의 예측 모델을 python으로 풀어보는 과정에 대해서 포스트를 할 것이다.
cyc1am3n.github.io
여기다.
잘 정리가 되어 있고, 소스도 잘 나와있어서.. 하나하나 따라 하면서 의미를 파악해보려고 한다.
여기 블로그 안 보고 저거 보는 게 더 좋을 수도 있겠다..
난 여기다가 내가 이해한 것과 내 생각을 좀 덧붙여볼 생각이다.
나만의 해석이 들어가 있어... 사실 틀릴 수 있겠지만, 최대한 이해하고 찾아가며 공부해보겠다.
어떻게 보면... 나 같은 쌩~~~ 초보는 내 것 보는 게 좀 좋을 수도 있겠다..ㅎㅎ
(눈높이가 맞으니...ㅎㅎ)
결국 남의 것을 가져오더라도.. 본인이 이해를 하느냐 못하느냐.. 그것이 중요한 것이닌깐!
그럼 시작..!
import pandas as pd
import numpy as np
#데이터 분석에 꼭 필요한 pandas 와 numpy를 import 시킨다.train = pd.read_csv('E:/kaggle_korea/2019-1st-ml-month-with-kakr/train.csv')
test = pd.read_csv('E:/kaggle_korea/2019-1st-ml-month-with-kakr/test.csv')
#train.csv 와 test.csv 파일을 pandas를 통해 읽어 온다.필요한 라이브러리를 import 시킨 후,
데이터를 읽어 온다.
train.head()읽어온 데이터를 확인해보자, 별다른 명령이 없으면 상위 5개의 데이터를 가지고 온다.
ex) head(10)
이렇게 한다면 10줄을 가지고 온다.
print('train data shape: ', train.shape)
print('test data shape: ', test.shape)
print('----------[train infomation]----------')
print(train.info())
print('----------[test infomation]----------')
print(test.info())
#shape는 데이터의 구조를 알려준다. (row수와 column수)
#info는 데이터 컬럼별 데이터 타입과 데이터가 몇건이 들어 있는지.. 뭐 그런거 알려주는것 같다.shape와 info 기능은 데이터 확인 및 개요 확인에 기본이 된다.
위 결과는 아래와 같다.
train data shape: (891, 12)
test data shape: (418, 11)
----------[train infomation]----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
----------[test infomation]----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
None
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set() # setting seaborn default for plots
#참고한 블로그에선 데이터 값의 분포를 보기위해 위 라이브러리를 불러온다고 했다.. 아마도 시각화 해서 보려고..
#seaborn은 데이터의 시각화를 위해 사용 하는것 같다.
#matplotlib 역시 데이터 시각화를 위해..(https://book.coalastudy.com/data-science-lv1/week2/stage4 참조)데이터 시각화 분석을 위해 matplotlib과 seaborn 라이브러리를 import 한다.
def pie_chart(feature):
feature_ratio = train[feature].value_counts(sort=False)
feature_size = feature_ratio.size
feature_index = feature_ratio.index
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
plt.plot(aspect='auto')
plt.pie(feature_ratio, labels=feature_index, autopct='%1.1f%%')
plt.title(feature + '\'s ratio in total')
plt.show()
for i, index in enumerate(feature_index):
plt.subplot(1, feature_size + 1, i + 1, aspect='equal')
plt.pie([survived[index], dead[index]], labels=['Survivied', 'Dead'], autopct='%1.1f%%')
plt.title(str(index) + '\'s ratio')
plt.show()
#여기 구문을 보면, pie_chart를 그려주기 위한것 같은데, 결과를 보면 알겠지만, 그 파이모양을 한 동그란 원 위에 색색 별로
#어떤 값의 크기를 나타내주는 챠트를 이야기 하는것 같다.
#소스를 대충 봐선 잘 모르겠지만 중간에 "Survived" 라는게 눈에 띄는데, 이는 아마 데이터 내에 다른 어떤 값
#sex, pclass, embarked 등의 값에 따른 "Survived" 값을 알기 위한게 아닌가 싶다.
#일단 소스를 실행 해보고 결과를 보고 유추해보도록 하자.파이 차트를 그려보자~!
pie_chart('Sex')결과에서 가장 큰 차트는 전체 train 데이터에서 성별의 분포를 나타 낸다.
그리고 아래 작은 두 개의 차트는 남, 녀 별 Survived 값에 따른 분포를 나타 낸다.
차트를 보니 위 소스가 뭐 하려고 하던 건지 한방에 이해가 된다.
pie_chart('Pclass')
#Pclass (티켓 클래스, 1이 가장 좋은것)
pie_chart('Embarked')
#Embarked (배를 어디서 탓는지, 탑승항구, 다른의미로 배를 언제 탔는지를 알 수 있겠다.)


여기까지 성별, 그리고 티켓 클래스, 탑승 항구에 따른 생존율이 어떻게 달라졌는지 유추해보자.
def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Survived','Dead']
df.plot(kind='bar',stacked=True, figsize=(10,5))데이터를 분석하는 데 있어서 데이터마다 알맞은 차트의 모양이 있다.
이번에는 Bar 타입의 차트를 통해서 데이터를 분석해 보자.
bar_chart("SibSp")
#SibSp (함께 탑승한 형제자매, 배우자의 수) 에 따른 생존률을 Bar 차트로 나타내 보자.
bar_chart("Parch")
#Parch (함께 탑승한 부모, 자녀의 수의 합) 에 따른 생존률도 보자.
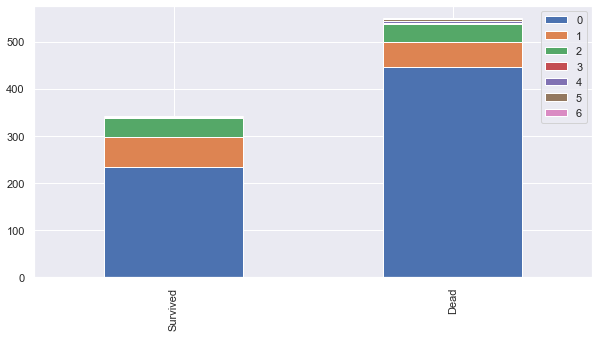
위 두 개의 Bar차트를 살펴본 결과, 내가 생각하기엔, 누군가(형제자매, 또는 부모, 자식)을 동반한 승객들의 생존율은
그렇지 않은 사람들에 비해 높게 나타나고 있음을 알 수 있다.
하지만, 이 데이터는 1차원적인 표면 데이터라고 할 수 있다. 이것들을 종합적으로 고려해야지 단순한 하나의 변수로써 생존율을 가늠하는것은 위험할 수 있기 때문이다.
아직 고려하지 않은 데이터들도 있고, 위에서 나타난 5개 변수에 따른 생존률 지표를 함께 고려해서 생존률을 다시 확인해보는 과정은 다음 포스트에 이어하도록 하겠다.
일단.. 오늘은 여기까지!
파란이의 데이터 분석 도전은 계속된다.
##2편 보러가기
2019/12/26 - [DB엔지니어가 공부하는 python] - [python 데이터분석] 캐글 타이타닉 따라해보기 #2
[python 데이터분석] 캐글 타이타닉 따라해보기 #2
# 캐글 타이타닉 따라해보기 2탄 입니다. 아마 타이타닉 따라하기는 마지막 편이 될 것 같습니다. 전편 보기 : 2019/12/26 - [DB엔지니어가 공부하는 python] - [python] 캐글 타이타닉 따라해보기 #1 [python] 캐..
stricky.tistory.com
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| [python] 텍스트 파일에서 명사만 뽑아서 명사별 빈도 카운트 하기 konlypy (0) | 2019.12.30 |
|---|---|
| [python 데이터분석] 캐글 타이타닉 따라해보기 #2 (1) | 2019.12.26 |
| [python] 기본이 되는 numpy (0) | 2019.12.26 |
| [python] 크롤러 만들어 db에 정보 insert 하기 (3) | 2019.12.24 |
| 데이터 분석을 위한 python 시작, 설치 해보자.. (0) | 2019.12.24 |


