캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (2)

안녕하세요.
지난번 넷플릭스 데이터를 이용한 데이터 분석 실습 1편에 이어서 2편을 작성 합니다.
지난 1편을 보시고 싶으신 분들은 아래 링크로 이동 하셔서 1편을 보시고 다시 2편을 봐주시면 됩니다.
2021/03/02 - [Data Science] - 캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (1)
캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (1)
캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (1) 오랫만에 데이터 분석 실습 포스트를 진행 합니다. 데이터 분석은 저도 아직.. 많이 허접한 실력을 가지고 있기 때문에, 이 글을 보시
stricky.tistory.com
분석을 위한 데이터 컬럼 추가 하기
자, 1편에서 데이터 클랜징을 다 했으니, 본격적인 분석을 위하여 몇가지 정보들을 나눠서 저장 하도록 하겠습니다. 우선 year 과 month 컬럼을 추가하여 date_added 컬럼에서 값을 추출 하여 넣도록 하겠습니다.
# year_added 컬럼 추가 하기
main_df['year_added'] = main_df['date_added'].apply(lambda x: x.split(" ")[-1])
# month_added 컬럼 추가 하기
main_df['month_added'] = main_df['date_added'].apply(lambda x: x.split(" ")[0])
# 추가한 컬럼 데이터 확인
main_df.head()추가된 두 컬럼을 확인 해봅니다.

다음은 target_ages 컬럼을 추가 합니다. 기존에 rating컬럼 값을 이용해서 시청 연령에 대한 값을 풀어서 저장 합니다.
코드는 다음과 같습니다.
ratings_ages = {
'TV-PG': 'Older Kids',
'TV-MA': 'Adults',
'TV-Y7-FV': 'Older Kids',
'TV-Y7': 'Older Kids',
'TV-14': 'Teens',
'R': 'Adults',
'TV-Y': 'Kids',
'NR': 'Adults',
'PG-13': 'Teens',
'TV-G': 'Kids',
'PG': 'Older Kids',
'G': 'Kids',
'UR': 'Adults',
'NC-17': 'Adults'
}
main_df['target_ages'] = main_df['rating'].replace(ratings_ages)
main_df['target_ages'].unique()아래와 같이 target_ages의 데이터 결과가 잘 출력 되었습니다.

데이터 타입 변경 하기
다음은 현재 있는데이터들의 데이터 타입을 변경 하겠습니다. 변경 한 내용은 코드내에 주석으로 달아 두었습니다.
# type 컬럼은 category로 변경 합니다.
main_df['type'] = pd.Categorical(main_df['type'])
# target_ages 역시 category 로 변경 합니다.
main_df['target_ages'] = pd.Categorical(main_df['target_ages'], categories=['Kids', 'Older Kids', 'Teens', 'Adults'])
# Year_added 는 integer로 변경 합니다. 그래야 released_year 데이터와 비교 할 수 있겠죠.
main_df['year_added'] = pd.to_numeric(main_df['year_added'])
main_df.dtypes아래와 같이 잘 변경이 되었군요!
데이터 시각화 하기
이젠 모든 데이터단의 준비가 되었습니다.
데이터를 시각화 하여 눈으로 직접 데이터를 파악 할 수 있도록 하겠습니다.
먼저, 아래 코드를 이용해서 넷플릭스내에 TV Show와 Movie의 비율을 확인 해보겠습니다.
plt.figure(figsize=(15, 7))
labels=['TV Show', 'Movie']
plt.pie(main_df['type'].value_counts().sort_values(),labels=labels,explode=[0.1,0.1],
autopct='%1.2f%%',colors=['red','royalblue'], startangle=90)
plt.title('Type of Netflix Content')
plt.axis('equal')
plt.show()결과는 아래와 같이 나옵니다.

이번에는 TV Show 와 Movie 두개의 dataframe을 각각 만들어서 각각의 시청 연령별 데이터를 뽑아 보겠습니다.
우선 하나의 데이터 셋을 TV Show와 Movie 기준으로 나누는 코드는 다음과 같습니다.
df_tv = main_df[main_df["type"] == "TV Show"]
df_movies = main_df[main_df["type"] == "Movie"]이렇게 하면 각각의 dataframe 으로 나눠 졌습니다.
그리고, 아래 코드를 이용해서 Movie의 시청 연령별 컨텐츠 건수를 확인 해보겠습니다.
movie_ratings = df_movies.groupby(['target_ages'])['show_id'].count().reset_index(name='count').sort_values(by='count',ascending=False)
fig_dims = (18,7)
fig, ax = plt.subplots(figsize=fig_dims)
sns.pointplot(x='target_ages',y='count',data=movie_ratings)
plt.title('Top Movie Ratings Based On Rating System',size='20')
plt.show()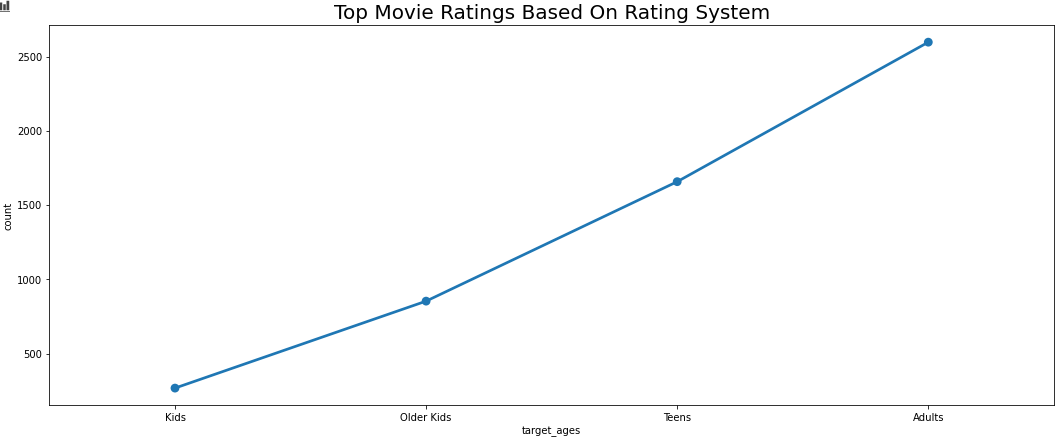
다음은 TV Show의 시청 연령별 컨텐츠 건수를 확인 하는 코드와 결과를 보겠습니다.
tv_ratings = df_tv.groupby(['target_ages'])['show_id'].count().reset_index(name='count').sort_values(by='count',ascending=False)
fig_dims = (18,7)
fig, ax = plt.subplots(figsize=fig_dims)
sns.pointplot(x='target_ages',y='count',data=tv_ratings)
plt.title('Top TV Show Ratings Based On Rating System',size='20')
plt.show()
다음은 TV Show와 Movie 전체 데이터를 가지고 rating 과 target_ages를 묶어서 각 rating이 어떤 target_ages에 속하고, 각 건수가 어떻게 되는지를 시각화 하기위한 내부 function을 만들고, 이 function을 이용하여 출력하는 코드를 작성 해보겠습니다.
# 함수 생성
def generate_rating_df(main_df):
rating_df = main_df.groupby(['rating', 'target_ages']).agg({'show_id': 'count'}).reset_index()
rating_df = rating_df[rating_df['show_id'] != 0]
rating_df.columns = ['rating', 'target_ages', 'counts']
rating_df = rating_df.sort_values('target_ages')
return rating_df
# 시각화 코드
rating_df = generate_rating_df(main_df)
fig = px.bar(rating_df, x='rating', y='counts', color='target_ages', title='Ratings of Movies And TV Shows Based On Target Age Groups', labels={'counts':'COUNT', 'rating':'RATINGS', 'target_ages':'TARGET AGE GROUPS' })
fig.show()아래와 같이 TARGET AGE GROUPS 별로 색상으로 시각화 되어 출력이 되었습니다.

자, 이번포스트는 여기서 한번 더 쉬어 가도록 하겠습니다.
다음편에 좀 더 본격적으로 시각화하는 실습 코드를 작성 해보겠습니다.
많은 도움이 되셨으면 좋겠습니다.
감사합니다.
# 다음편 보러가기 #
2021.03.09 - [Data Science] - 캐글 데이터 시각화 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (3)
캐글 데이터 시각화 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (3)
캐글 데이터 시각화 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (3) 캐글의 넷플릭스 데이터를 이용한 데이터 분석 3번째 시간 입니다. 이번편은 종전에 데이터 전처리를 하고, 일부 데이
stricky.tistory.com
#본 실습은 아래 데이터 실습 코드를 번역 및 일부 수정하며 진행되고 있음을 알려드립니다.
www.kaggle.com/bhartiprasad17/netflix-movies-and-tv-shows-eda
by.sTricky
'Data Science' 카테고리의 다른 글
| [python 데이터 분석 실습] 코로나 19 2021 현재 시점 분석하기 1편 (0) | 2021.03.29 |
|---|---|
| 캐글 데이터 시각화 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (3) (0) | 2021.03.09 |
| 캐글 넷플릭스(netflix) 데이터를 이용한 데이터 분석 실습 (1) (0) | 2021.03.02 |
| Rain in Australia 캐글 날씨 데이터셋 다운로드 받아 mysql에 넣는 방법 (0) | 2021.02.17 |
| Softmax Regression 기본 개념 파악 및 실습하기 | sTricky (0) | 2021.02.07 |



