안녕하세요.
파이썬으로 데이터 분석 공부하고 있는 sTricky 입니다.
오늘은 유튜브 영상을 보고 따라하며 민간아파트 분양가격 데이터를 분석 하는 실습을
해보겠습니다.
아마, 몇편으로 나뉠지는 모르겠지만, 한편으로 끝날것 같지는 않습니다.
우선 보고 따라는 실습 영상 올릴께요.
위 영상을 보고 진행을 해보겠습니다.
우선 데이터를 다운로드 받습니다.
데이터는 공공데이터포털에서 받습니다.
여긴 정말 유용한 데이터가 많이 있으니, 종종 들어가보시면 참고가 될만한 자료를 찾으실수 있을겁니다.
https://www.data.go.kr/dataset/3035522/fileData.do
공공데이터포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Dataset)와 Open API로 제공하는 사이트입니다.
www.data.go.kr
위 링크에서 데이터 다운 받으시고 실습준비를 하시면 됩니다.
동영상도 참고 하시면서 따라하시면 됩니다.
동영상에서는 온라인 분석도구인 Colaboratory를 이용하지만 전 jupyter notebook을 이용해서
실습을 진행 했습니다.
이 점 참고 부탁드립니다.
우선 시각화 도구를 먼저 설치 하겠습니다.
!pip3 install plotnine
!pip3 install missingnopandas와 numpy, re (정규표현식)을 import 하겠습니다.
import pandas as pd
import numpy as np
import re
from plotnine import *그리고, 위에서 다운로드한 엑셀 파일을 pandas로 가져옵니다.
데이터 크기도 확인해 봅니다.
pre_sale = pd.read_csv('E:/datas/주택도시보증공사_전국 평균 분양가격(2019년 11월).csv', encoding='euc-kr')
pre_sale.shape(행,열)
데이터를 미리보기 합니다.
마지막 데이터도 한번 확인해 봅니다.
pre_sale.head()
#데이터의 앞부분 미리보기
pre_sale.tail()
#데이터의 뒷부분 미리보기데이터 타입에 따른 요약 보기를 합니다.
중간에 있는 숫자는 NaN이 아닌 건수의 정보 입니다.
분양가격이 숫자 타입이 아닌걸 알수 있습니다. 숫자 타입으로 변경해줄 필요가 있습니다.
pre_sale.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4250 entries, 0 to 4249
Data columns (total 5 columns):
지역명 4250 non-null object
규모구분 4250 non-null object
연도 4250 non-null int64
월 4250 non-null int64
분양가격(㎡) 3982 non-null object
dtypes: int64(2), object(3)
memory usage: 166.1+ KB
혹은 아래와 같이 컬럼명과 데이터 타입만 볼수도 있습니다.
pre_sale.dtypes결측치를 숫자로 확인해 봅니다.
pre_sale.isnull().sum()missingno 라이브러리를 이용해서 결측치는 컬럼별 그래프로 확인 해 봅니다.
#컬럼별 결측치 확인
import missingno as msno
msno.matrix(pre_sale, figsize=(18,6))
결측치를 확인하는데서 한글이 깨지네요..
이부분은 해결법을 찾아 봐야 할 것 습니다.
그래프 상으로 비어 있는 부분이 데이터 값이 없는 결측치 부분입니다.
한글이 깨져 잘 안보이는 분양가격이 지금 결측 데이터가 있는것으로 확인 됩니다.
이젠 데이터를 좀 가공할 차례 입니다.
우선 '연도' 와 '월' 컬럼을 string type 으로 변경 하겠습니다.
pre_sale['연도'] = pre_sale['연도'].astype(str)
pre_sale['월'] = pre_sale['월'].astype(str)그리고, '분양가격(㎡)' 컬럼을 이용해서 pre_sale_price 라는 셋을 새로 만듭니다.
pre_sale_price = pre_sale['분양가격(㎡)']또한 분양가격의 타입을 숫자로 변경하여 다시 넣어줍니다.
더불어 평탕 분양가격도 추가해 줍니다.
# 분양가격의 타입을 숫자로 변경해 줍니다.
pre_sale['분양가격'] = pd.to_numeric(pre_sale_price, errors='coerce')
# 평당 분양가격을 구해볼까요.
pre_sale['평당분양가격'] = pre_sale['분양가격'] * 3.3잘 변경이 되었는지 info()를 통해서 확인 합니다.
pre_sale.info()data type이 float 나 int 로 되어 있는것들은 기본적으로
describe 기능을 이용 해서 데이터 요약을 해볼수 있습니다.
pre_sale.describe()옵션을 변경하면 object type의 데이터도 요약을 확인 할 수 있습니다.
pre_sale.describe(include=[np.object])특정 연도의 데이터만 확인해 봅니다.
그리고, pre_sale_2018 이라는 데이터 셋을 만들어 봅니다.
# 2018년 데이터만 봅니다.
pre_sale_2018 = pre_sale.loc[pre_sale['연도'] == '2018']
pre_sale_2018.shape이 데이터 셋에서는 시도별로 데이터 건수가 동일 하다는것을 group by 해서 확인 할 수 있습니다.
# 같은 값을 갖고 있는 걸로 시도별로 동일하게 데이터가 들어 있는 것을 확인할 수 있습니다.
pre_sale['규모구분'].value_counts()데이터를 읽게 쉽게 변경하고,
2015년부터 2019년까지 데이터의 요약을 해 봅니다.
# 숫자를 읽기 쉽게 하기 위해 지정
pd.options.display.float_format = '{:,.0f}'.format
# 분양가격만 봤을 때 2015년에서 2018년으로 갈수록 오른 것을 확인할 수 있습니다.
pre_sale.groupby(pre_sale.연도).describe().T전체를 대상으로 규모구분으로 group by 한 데이터 요약을 확인 해 봅니다.
pre_sale.pivot_table('평당분양가격', '규모구분', '연도')규모구분에서 전체로 되어있는 데이터만 가져와서 새로운 데이터 셋을 만듭니다.
# 규모구분에서 전체로 되어있는 데이터만 가져온다.
region_year_all = pre_sale.loc[pre_sale['규모구분'] == '전체']
region_year = region_year_all.pivot_table('평당분양가격', '지역명', '연도').reset_index()해당 데이터를 이용해서 년도별 변동액을 알아보는 표와, 요약 보고문장을 만들어 봅니다.
region_year['변동액'] = (region_year['2019'] - region_year['2015']).astype(int)
max_delta_price = np.max(region_year['변동액'])*1000
min_delta_price = np.min(region_year['변동액'])*1000
mean_delta_price = np.mean(region_year['변동액'])*1000
print('2015년부터 2019년까지 분양가는 계속 상승했으며, 상승액이 가장 큰 지역은 제주이며 상승액은 평당 {:,.0f}원이다.'.format(max_delta_price))
print('상승액이 가장 작은 지역은 울산이며 평당 {:,.0f}원이다.'.format(min_delta_price))
print('전국 평균 변동액은 평당 {:,.0f}원이다.'.format(mean_delta_price))
region_year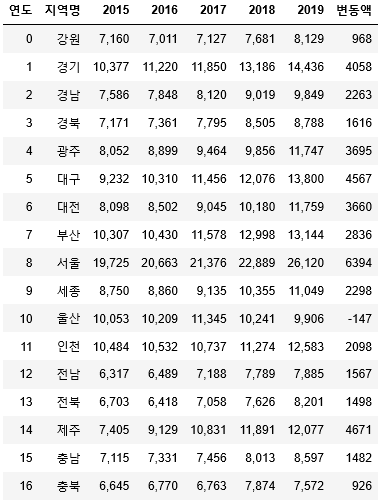
자, 오늘은 여기까지 하고,
다음편에서는 시각화된 그래프로 데이터 분석을 하는 포스팅을 이어서 하도록 하겠습니다.
감사합니다.
by.sTricky
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| [python] 파이썬으로 네이버 카페 게시판 크롤링 & 워드 클라우드 실습 하기! (feat.konlpy.Twitter) (2) | 2020.01.10 |
|---|---|
| [python] 파이썬으로 주식 상장기업 크롤링한 데이터 엑셀 저장 및 엑셀 파일 불러오기 feat.pandas (2) | 2020.01.09 |
| [python] jupyter notebook 에서 디버깅 (debug) 하기 #ipdb 명령어 (0) | 2020.01.03 |
| [python] 인터넷이 안되는곳에서 파이썬 패키지 설치하기! (pip download) (2) | 2020.01.03 |
| [python] 텍스트 파일에서 명사만 뽑아서 명사별 빈도 카운트 하기 konlypy (0) | 2019.12.30 |



