파이썬 데이터 분석 범죄 데이터 실습

안녕하세요.
파이썬으로 하는 데이터 분석 실습!
범죄 데이터 분석 입니다. 각종 범죄들의 수치를 생활수준, 결혼 여부로 나누어 정리한 데이터가 공공데이터 포털에 있길래 가지고 와서 분석을 해보았습니다. 그냥 간단하게 분석하였습니다. 좀 더 세세한 분석이 있으려면 지금 데이터 말고 더욱 많은 정보가 담겨 있는 데이터를 구해야 할 것 같아요..ㅠ
어떤 범죄가 많이 일어나고 있는지, 그리고 각 범죄별 범인들의 결혼 여부와 생활 수준에 대해서 한번 그래프로 시각화했습니다. 사실 이중 도넛 차트라든지 다른 멋진 차트들을 가지고 하고 싶었는데 아직 역량 부족이라.. 다음번에 꼭 더 멋진 시각화 툴로 돌아올 수 있도록 하겠습니다.
자, 그럼 바로 시작 하겠습니다.
우선 데이터를 가지고 옵니다.
https://www.data.go.kr/dataset/3074470/fileData.do
공공데이터포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Dataset)와 Open API로 제공하는 사이트입니다.
www.data.go.kr
데이터는 공공데이터 포털에서 가지고 왔습니다. 위 링크를 타고 들어가서 아래와 그림과 같이 파일을 다운로드하시면 됩니다.

이젠 jupyter notebook을 켜고, 시작하겠습니다.
1. 필요한 라이브러리를 가지고 옵니다.
import numpy as np
import pandas as pd
import pymysql
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
#데이터 분석에 필요한 pandas 와 numpy를 import 시킨다.
2. 위에서 다운로드한 파일을 불러옵니다.
crime = pd.read_csv('C:/Users/whiki/crime_2016.csv', engine='python')
#범죄데이터 파일을 pandas를 통해 읽어 온다.3. 데이터를 확인해 봅니다.
crime
4. 그래프를 그리기 전에 한글 오류를 해결합니다.
plt.rc('font', family='NanumGothic')
print(plt.rcParams['font.family'])5. 데이터의 개요를 확인해 봅니다.
print('crime data shape: ', crime.shape)
print('----------[crime infomation]----------')
print(crime.info())
#shape는 데이터의 구조를 알려준다. (row수와 column수)
6. 데이터를 직접 보면 각 범죄 카테고리가 row로 있는데, 범죄와 상관없이 생활정도별로 각 범죄별 데이터의 합계를 구해서 따로 DataFrame을 만들어 줍니다.
life_level.loc[0] = {'level_nm':'low','cnt':crime['생활정도(하류)'].sum()}
life_level.loc[1] = {'level_nm':'mid','cnt':crime['생활정도(중류)'].sum()}
life_level.loc[2] = {'level_nm':'high','cnt':crime['생활정도(상류)'].sum()}7. 그리고 level_nm을 DataFrame의 인덱스로 지정해 줍니다.
life_level=life_level.set_index("level_nm")8. 파이형 그래프로 생활수준별 범죄 비율을 그려봅니다.
group_colors = ['yellowgreen', 'lightskyblue', 'lightcoral']
group_explodes = (0.1, 0, 0)
plot = life_level.plot.pie(subplots=True, y='cnt', figsize=(7, 7),shadow=True,startangle=90,explode = group_explodes,colors=group_colors,autopct='%1.2f%%')
생활정도가 하류인 쪽에서 많은 범죄가 발생하고, 중류, 상류로 나타나고 있습니다. 하지만 그렇다고 하류 쪽에 있는 사람들이 더 높은 비율로 범죄를 저지른다고 속단할 수는 없습니다. 하류에 속하는 사람이 더 많을테닌깐요. 전체 수를 알고 다시 비교를 해야 범죄율을 알 수 있을 것입니다.
9. 이번에는 각 범죄 카테고리별 전체 범죄 건수를 합쳐보겠습니다.
crime['합계'] = crime['생활정도(하류)']+crime['생활정도(중류)']+crime['생활정도(상류)']+crime['생활정도(미상)']
합계 칼럼이 잘 들어가 있는 것을 확인할 수 있습니다.
10. 각 범죄별 건수를 막대그래프로 표현하였습니다.
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 0) #x축 조절
sns.barplot(
data = crime.sort_values(by='합계', ascending=False),
x = "합계",
y = "범죄중분류"
)
plt.show()
교통범죄, 기타 범죄가 1,2위입니다 이것을 빼면 사기와 폭행, 절도가 뒤를 따르고 있습니다. 우리나라 범죄만의 특징이 있다고 하는데, 바로 사기가 다른 나라에 비해 높다란 것입니다. 데이터에서도 나타나고 있습니다.
11. 이번에는 결혼 여부에 따른 범죄 건수를 비교해 보겠습니다.
crime['혼인_합계'] = crime['혼인관계(유배우자)']+crime['혼인관계(동거)']+crime['혼인관계(이혼)']+crime['혼인관계(사별)']
crime['미혼_합계'] = crime['미혼자부모관계(실(양)부모)']+crime['미혼자부모관계(계부모)']+crime['미혼자부모관계(실부계모)']+crime['미혼자부모관계(실부무모)']+crime['미혼자부모관계(실모계부)']+crime['미혼자부모관계(실모무부)']+crime['미혼자부모관계(계부무모)']+crime['미혼자부모관계(계모무부)']+crime['미혼자부모관계(무부모)']혼인 및 미혼의 합계를 구해서 새로운 칼럼에 넣었습니다.
12. 범죄 중분류와 혼인, 미혼 합계를 새로운 DataFrame으로 만들어 줍니다.
crime_m = crime[['범죄중분류','혼인_합계','미혼_합계']]
crime_m=crime_m.set_index("범죄중분류")13. 두 그룹 간의 비교 그래프를 막대그래프로 그려봅니다.
ax=crime_m.sort_values(by='혼인_합계', ascending=False).plot(kind='bar', title='범죄분석', figsize=(16, 8), legend=True, fontsize=12)
ax.set_xlabel('범죄중분류', fontsize=12) # x축 정보 표시
ax.set_ylabel('범죄건수', fontsize=12) # y축 정보 표시
ax.legend(['혼인_합계', '미혼_합계'], fontsize=12) 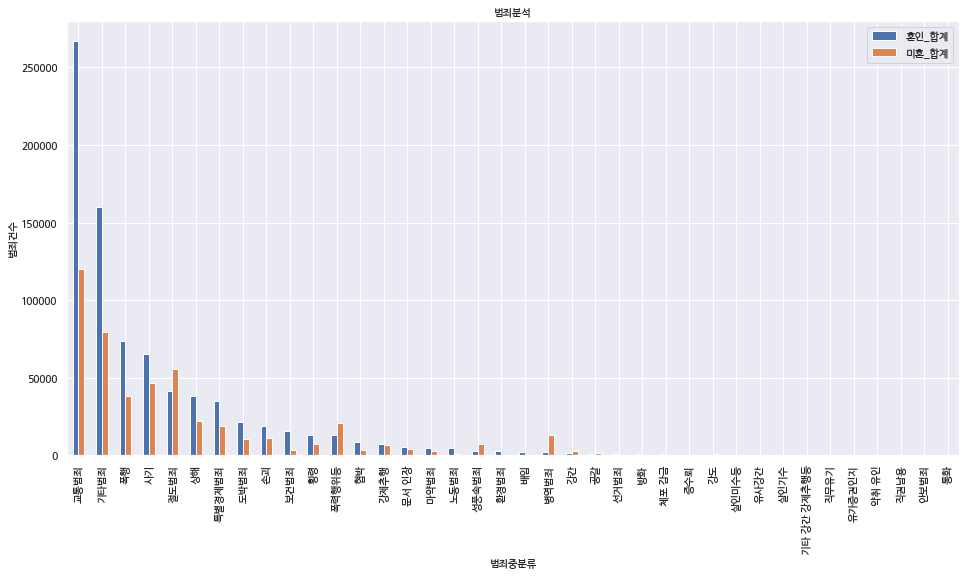
교통범죄와 기타 범죄를 빼고 보면, 폭행, 사기에서는 기혼자들의 범죄가 미혼자보다 높다는 걸 확인할 수 있습니다. 하지만 절도범죄, 폭력행위, 성풍속범죄, 병역범죄 등에서는 미혼자들의 범죄 건수가 기혼자보다 더 많이 있다는 걸 알 수 있는 도표입니다.
이렇게 오늘은 간단하게 범죄 관련 지표를 이용해서 데이터 분석을 해보았습니다.
데이터 분석 실력도 실력이지만, 이 데이터에는 생각보다 확인해볼 만한 내용이 별로 없었습니다. 딱 보는 순간 괜찮아 보여서 가지고 왔는데...ㅎㅎ 다음에 더 좋은 데이터 분석으로 찾아오겠습니다. 감사합니다!!!
by.sTricky
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| 파이썬 딕셔너리 알고리즘 동명이인 찾기 2 #12 (5) | 2020.03.12 |
|---|---|
| 파이썬 큐와 스택 알고리즘 회문 찾기, palindrome #11 (4) | 2020.03.11 |
| 파이썬 이분탐색 알고리즘 Binary search #10 (4) | 2020.03.09 |
| 파이썬 병합정렬 알고리즘 merge sort #9 (8) | 2020.03.06 |
| 파이썬 상가(상권)데이터를 이용해서 내 주변 동네 약국 위치 분석 feat.코로나19 마스크 약국 (12) | 2020.03.05 |



