파이썬 상권분석 실습# 상가(상권)데이터를 이용한 데이터 분석 #1

안녕하세요.
파이썬을 이용해서 상가(상권) 분석을 해보도록 하겠습니다.
상가(상권) 데이터는 지난번에 공공데이터 포털에서 다운로드한 데이터입니다. 아래 링크로 가시면 해당 데이터를 손쉽게 손에 넣으실 수 있습니다.
[python_상가(상권)정보DB가지고놀기]공공데이터포털 에서 상가(상권)정보DB 다운 받아 DB에 insert 하기 #1
[python_상가(상권)정보DB가지고놀기]공공데이터포털 에서 상가(상권)정보DB 다운 받아 DB에 insert 하기 #1 안녕하세요. 이번에는 지난번 주소DB에 이어 상가(상권) 정보 DB를 공공데이터 포털에서 다운로드하여..
stricky.tistory.com
이젠 혼자서 해보는 데이터 분석 2번째 시간입니다.
이번 상가(상권)데이터를 가만히 보다 보니 분석할게 엄청 많이 있는 것 같습니다. 한 번에 다 하기는 너무 힘들 것 같아, 몇 편에 걸쳐서 진행하는 방향으로 하겠습니다.
우선 이번 시간에는 데이터를 DB에서 python DataFrame으로 가지고 와서 전국의 인구데이터와 비교해서 상가가 어떤 지역에 얼마나 있는지 확인해보겠습니다.
두 번째, 편의점 데이터를 가지고 간단하게 브랜드 별, 지역별 수 등을 파악해 보겠습니다.
세 번째, 상가를 9가지 대분류로 묶어서, 특정 도시에 어떻게 분포하고 있는지와, 특색이 있는 두 도시 간 어떤 상가가 얼마나 있는지 분석해보도록 하겠습니다.
#사전에 미리 말씀드리지만, 저 혼자서 독학으로 python을 이용한 데이터 분석을 진행 하며 공부하고 있습니다. source 상에 비효율적이거나, 필요 없는 과정이 포함되어 있을 수.... 아니 포함되어 있을 겁니다. 더 좋은 방법이나, 분석도구가 있다면 무분별한 비난보다는 가르침을 댓글에 표현해주시면 정말 감사히 알려주신 부분을 실습해보도록 하겠습니다.
자~ 그럼 렛츠 기릿!!!
1. jupyter notebook을 실행 합니다. 그리고 필요한 라이브러리를 import 합니다.
import pandas as pd
import pymysql
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
2. 한글 글꼴을 지정 합니다. 전 이 과정을 안 하면 그래프 안에서 한글이 깨지더라고요.
plt.rc('font', family='NanumGothic')
print(plt.rcParams['font.family'])
3. DB와 연결을 합니다. 일부 접속 정보는 'x'로 마스킹하였습니다.
# db connect
conn = pymysql.connect(host='localhost',
user = 'xxx', password='xxx', db = 'store_svc_m',charset = 'utf8')
curs = conn.cursor(pymysql.cursors.DictCursor)
4. 상가(상권) 데이터를 가지고 와서 df에 입력합니다.
sql = "select * from store_info_m"
curs.execute(sql)
store_info = curs.fetchall()
df = pd.DataFrame(data=store_info)
5. 데이터를 확인해봅니다.
df.head
6. 상가(상권) 데이터중에서 상권 업종 대분류명으로 group by count 합니다.
df_big_shop_cnt=df['bsn_sector_big_nm'].value_counts()
# group by count 상권대분류
7. 데이터가 잘 들어갔는지 확인합니다.
df_big_shop_cnt.head
8. 간단하게 그래프를 그려 봅니다.
df_big_shop_cnt.plot.bar()
plt.xticks(rotation=50)
#plt.show()
#상권대분류 그래프 
전국적으로 음식과 소매 업종이 가장 많고, 생활서비스 부분에 많은 상가가 있다는 것을 알 수 있습니다. 역시, 먹고, 사는 것들이 가장 많이 있네요.
9. 상가(상권) 데이터 중에서 시도명으로 group by count 합니다.
df_sd_shop_cnt=df['sd_nm'].value_counts()
# group by count 시도분류
10. 시도명을 기준으로 나온 count 값을 그래프로 그려 봅니다.
df_sd_shop_cnt.plot.bar()
plt.xticks(rotation=50)
#plt.show()
#시도분류 그래프 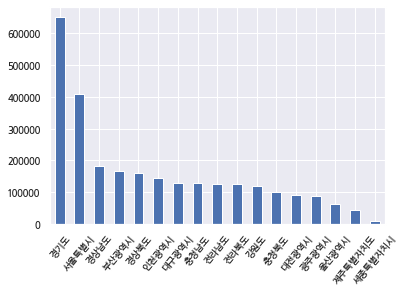
역시나 경기도와 서울에 상가들이 가장 많이 있군요. 그 뒤를 경상남도, 부산 등이 따라오고 있습니다. 아무래도 가장 작은 분류인 세종특별자치시가 가장 적습니다.
11. 이번에는 전국 인구수를 가지고 오겠습니다. 각 시도별 인구 대비 상가의 수를 비교해보기 위해서입니다. 전국 시도별 인구수는 아래 링크에서 구하여, DB에 넣었습니다.
http://www.index.go.kr/potal/main/EachDtlPageDetail.do?idx_cd=1007
sql = "select sd_nm, year2018 from population_info_m"
curs.execute(sql)
pop_info = curs.fetchall()
df_pop = pd.DataFrame(data=pop_info)
#전국 시도별 인구수 가져오기
12. 잘 가지고 왔는지 확인합니다. 참고로 2018년 인구 데이터입니다.
df_pop.head
13. 현재 위에서 사용했던 'df_sd_shop_cnt' 시도별 상가수 데이터는 시리즈 타입으로 되어 있는 습니다. 이것을 DataFrame으로 바꾸고 칼럼명을 조금 조정하겠습니다.
df_sd_shop_cnt=df_sd_shop_cnt.to_frame().reset_index()
# 시리즈 타입을 DataFrame으로 변경하기
df_sd_shop_cnt = df_sd_shop_cnt.rename({'index':'sd_nm','sd_nm':'shop_cnt'},axis='columns')
# 컬럼명을 변경하기
df_sd_shop_cnt
# 잘 바뀌었나 확인
14. 그럼 위에서 인구 데이터를 가지고 왔었는데, 그 인구 데이터셋에 상가수 데이터를 시도명 기준으로 합쳐주겠습니다.
df_sd_pop_shp_cnt=pd.merge(df_pop,df_sd_shop_cnt,on='sd_nm', right_index=True)
# 데이터셋 merge 하기
df_sd_pop_shp_cnt
# 데이터 확인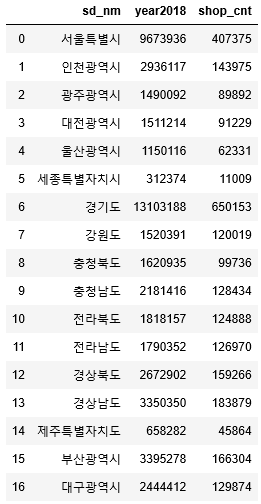
15. 깔끔하게 잘 합쳐졌습니다. 그러나 인구수와 상가수는 단순하게 숫자 차이가 너무 많이 나기 때문에 이걸로 그래프 그리면 한눈에 잘 비교가 되지 않습니다. 그래서 인구와 상가수를 각각의 전체 건수로 나누어 시도별 그 비율로 그래프를 그리기 위해 칼럼을 추가하고 각 비율 수치를 구하여 넣도록 하겠습니다.
df_sd_pop_shp_cnt['pop_rate']=df_sd_pop_shp_cnt['year2018']/df_sd_pop_shp_cnt['year2018'].sum()*100
# 시도별 인구수 비율을 구하여 컬럼 추가 합니다.
df_sd_pop_shp_cnt['shop_rate']=df_sd_pop_shp_cnt['shop_cnt']/df_sd_pop_shp_cnt['shop_cnt'].sum()*100
# 시도별 상가수 비율을 구하여 컬럼 추가 합니다.
df_sd_pop_shp_cnt
# 데이터를 확인 합니다.
16. 우선 각 시도별 인구수 비율을 그래프로 그려 보겠습니다.
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 0) #x축 조절
sns.barplot(
data = df_sd_pop_shp_cnt.sort_values(by='pop_rate', ascending=False),
x = "pop_rate",
y = "sd_nm"
)
plt.show()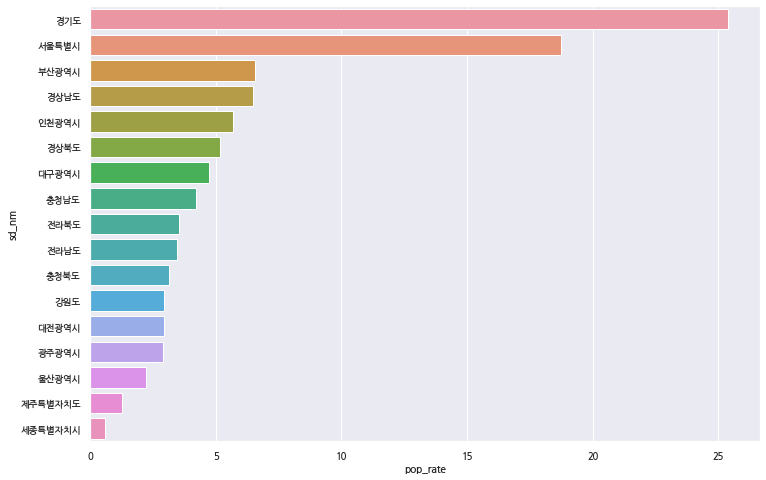
경기도가 약 25%를 넘고, 서울이 약 18% 정도로 나타나고 있습니다. 둘이 합쳐서 43%가 넘네요. 얼마 전에 수도권 인구수가 전체 인구수의 50%를 넘었다고 하던데, 여기에 인천광역시 5% 정도를 더하면 2018년도에 이미 48% 정도를 차지하고 있었네요.
17. 이번에는 인구비 율대 상가비율을 각 시도별로 붙여서 그래프로 표현해 보겠습니다.
df_sd_pop_shp_rate=df_sd_pop_shp_cnt[["sd_nm","pop_rate","shop_rate"]]
# 새로운 데이터셋에 시도명, 인구비율, 상가비율 데이터만 가지고 와서 넣습니다.
df_sd_pop_shp_rate=df_sd_pop_shp_rate.set_index("sd_nm")
# 시도명을 새로운 인덱스로 지정 합니다.
ax=df_sd_pop_shp_rate.sort_values(by='pop_rate', ascending=False).plot(kind='bar', title='상권분석', figsize=(12, 8), legend=True, fontsize=12)
ax.set_xlabel('시도명', fontsize=12) # x축 정보 표시
ax.set_ylabel('비율', fontsize=12) # y축 정보 표시
ax.legend(['인구비율', '상가비율'], fontsize=12)
# 그래프를 그려줍니다.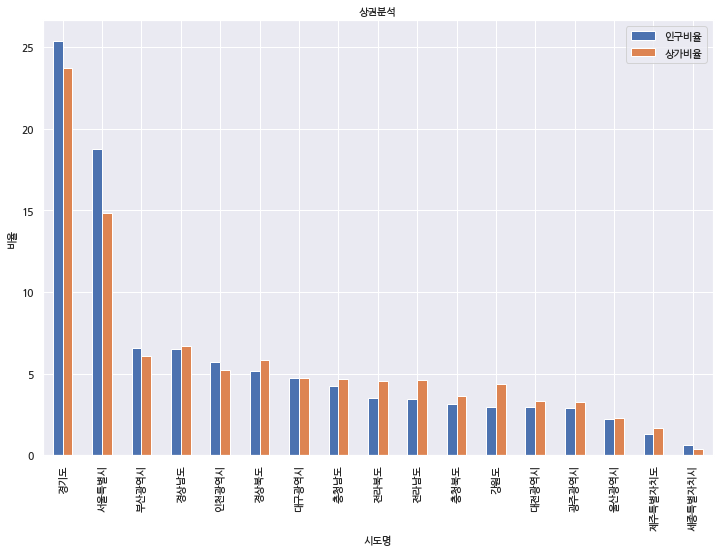
이 그래프에서 알 수 있는 것은 어떤 시도에 인구가 어느 정도 있는데 상가가 어느정도 있는가를 볼 수 있겠습니다.
경기도와 서울은 인구에 비해 상가가 그렇게 많은 편은 아닌 것으로 보입니다. 대형 상가가 많고, 사람들이 밀집되어 있다 보니 작은 상가들이 곳곳에 있는 지방 소도시에 비해 상가가 많지 않은 것 같습니다.
경상남도, 경상북도, 충청남도, 충청북도, 전라남도, 전라북도, 강원도 등 지방으로 갈수록 인구에 비해 상가가 많은걸 확인할 수 있는데, 인구 밀집도가 낮은 쪽으로 상가들이 곳곳에 넓게 분포되어 있어 그렇지 않을까 추측이 됩니다. 여러분들은 이 그래프를 어떻게 해석하실까요? 댓글로 남겨주시면 감사하겠습니다.
18. 이번에는 대형 편의점인 CU, GS25, 세븐일레븐 중 어떤 편의점이 얼마나 있는지 확인해 보겠습니다. 우선 편의점 데이터를 DB에서 가지고 오겠습니다.
sql = "select store_nm, count(*) from store_info_m where bsn_sector_small_cd = 'D03A01' and store_nm in ('CU','GS25','세븐일레븐') group by store_nm"
curs.execute(sql)
cvn_info = curs.fetchall()
df_cvn = pd.DataFrame(data=cvn_info)
# 편의점 브랜드별 카운트
df_cvn
# 데이터 확인
19. store_nm을 새로운 인덱스로 지정합니다. 그리고 그래프를 그려 줍니다.
df_cvn=df_cvn.set_index("store_nm")
# 새로운 인덱스 지정
group_colors = ['yellowgreen', 'lightskyblue', 'lightcoral'] # 색상지정
group_explodes = (0.1, 0, 0) # 제일 많은 값의 슬라이스를 분리하여 강조
plot = df_cvn.plot.pie(subplots=True, y='count(*)', figsize=(7, 7),shadow=True,startangle=90,explode = group_explodes,colors=group_colors,autopct='%1.2f%%')
# pie 그래프 작성
CU 편의점이 가장 많이 있네요, 개인적으로는 GS25를.... 우리 집 근처에는 GS25가 더 많이 있는 것 같은데, 소수의 비율을 보여주는 건 파이 형태의 원형 그래프가 적당 한 것 같습니다.
20. 이번에는 각 시도별도 편의점(3사)이 얼마나 있는지 그 비율을 구해 보도록 하겠습니다. 우선 데이터를 가지고 오고, 그래프를 그려보도록 하겠습니다.
sql = "select sd_nm, count(*) from store_info_m where store_nm in ('CU','GS25','세븐일레븐') group by sd_nm"
curs.execute(sql)
cvn_info = curs.fetchall()
df_sd_cvn = pd.DataFrame(data=cvn_info)
# 지역별 편의점 카운트
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 50) #x축 조절
sns.barplot(
data = df_sd_cvn[['sd_nm','count(*)']].sort_values(by='count(*)', ascending=False),
x = "sd_nm",
y = "count(*)"
)
plt.show()
# 그래프 그리기
인구수나 가게수와 거의 유사한 그래프가 나오고 있습니다. 뭐 당연한 거겠죠? 다만 중위권 순서가 인구수나 상가수와는 조금 달라졌으나 크게 의미가 있지는 않은 것 같습니다.
21. 이번에는 인구비율 대비 편의점 비율과 상가비율을 함께 비교해보겠습니다.
df_sd_cvn['cvn_rate']=df_sd_cvn['count(*)']/df_sd_cvn['count(*)'].sum()*100
# 우선 편의점 건수가 있던 데이터셋에 컬럼을 추가하여 전체대비 비율을 구해서 넣습니다.
df_sd_pop_cvn_rate=df_sd_pop_shp_cnt[["sd_nm","pop_rate","shop_rate"]]
# 위에서 사용했던 인구수, 상가수 데이터셋에서 시도명, 인구비율, 상가비율 데이터를 가지고와서 새로운 데이터 셋을 만듭니다.
df_sd_pop_cvn_rate=pd.merge(df_sd_pop_cvn_rate,df_sd_cvn,on='sd_nm', right_index=True)
# 여기에다가 편의점수 및 비율 데이터셋을 merge 합니다.
del df_sd_pop_cvn_rate["count(*)"]
# 그리고 필요없는 편의점 count 컬럼을 삭제 합니다.
# 이렇게 하고 데이터넷을 확인 해 보겠습니다.
df_sd_pop_cvn_shp_rate
22. 그러고 나서 그래프를 그려봅니다.
ax=df_sd_pop_cvn_shp_rate.sort_values(by='pop_rate', ascending=False).plot(kind='bar', title='상권분석', figsize=(12, 8), legend=True, fontsize=12)
ax.set_xlabel('시도명', fontsize=12) # x축 정보 표시
ax.set_ylabel('비율', fontsize=12) # y축 정보 표시
ax.legend(['인구비율', '편의점비율','상가비율'], fontsize=12)
# 그래프 그리기
편의점 수 역시 대도시보다는 지방에 인구 대비 많은 것을 확인할 수 있습니다. 상가수나 편의점 수는 인구밀도와 밀접한 관계가 있는 것으로 보입니다. 인구수, 상가수, 편의점 수가 대부분 비슷한 곳은 울산광역시밖에 없는 것 같습니다.
23. 이번에는 제주특별자치도에 있는 상가들을 업종 대분류 코드로 group by count 하여 어떤 업종에 상가가 얼마나 있는지 확인해보겠습니다.
sql = "select bsn_sector_big_nm, count(*) from store_info_m where sd_nm = '제주특별자치도' group by bsn_sector_big_nm"
curs.execute(sql)
jeju_info = curs.fetchall()
df_jeju_shp = pd.DataFrame(data=jeju_info)
# 제주특별자치도 상가 대분류 카운트
df_jeju_shp
# 데이터 확인
24. 업종 대분류 코드를 이용하여 count 한 결과를 그래프로 나타내 보겠습니다.
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 0) #x축 조절
sns.barplot(
data = df_jeju_shp.sort_values(by='bsn_sector_big_nm', ascending=False),
x = "bsn_sector_big_nm",
y = "count(*)"
)
plt.show()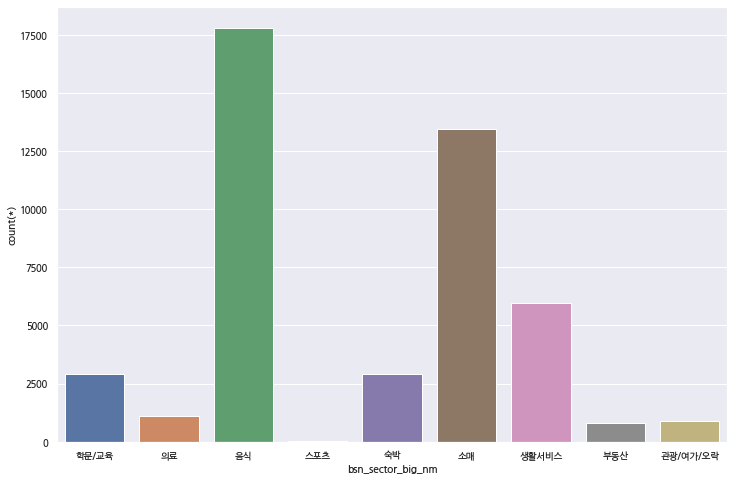
음식점과 소매업의 비중이 높은 것을 확인할 수 있습니다. 위에서 확인했던 전국적인 데이터와 유사해 보입니다.
25. 이번에는 제주특별자치도와 인구수가 유사 하지만 도시 특색이 전혀 다른 안산시의 데이터를 확인해 보겠습니다. 참고로 제주특별자치도의 인구는 약 67만 명, 안산시는 65만 명 정도입니다. 두 도시의 특색은 여러분들도 잘 아시다시피 각각 관광도시, 공업 도시의 특색을 가지고 있습니다.
sql = "select bsn_sector_big_nm, count(*) from store_info_m where sgg_nm like '안산시%' group by bsn_sector_big_nm"
curs.execute(sql)
ansan_info = curs.fetchall()
df_ansan_shp = pd.DataFrame(data=ansan_info)
# 안산시 상가 대분류 카운트
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 0) #x축 조절
sns.barplot(
data = df_ansan_shp.sort_values(by='bsn_sector_big_nm', ascending=False),
x = "bsn_sector_big_nm",
y = "count(*)"
)
plt.show()
# 그래프 그리기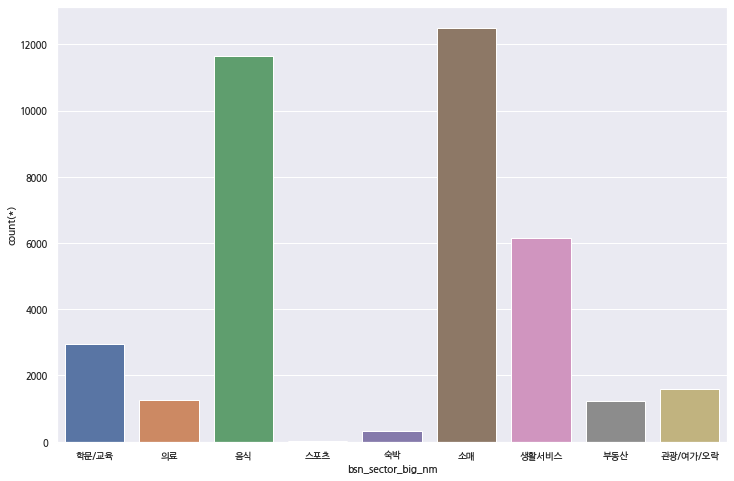
이렇게 각각의 그래프로 나타내닌깐 한눈에 잘 들어오지 않습니다. 역시 음식과 소매업이 많이 있는 건 알 수 있습니다.
26. 두 도시의 지표를 합쳐 보겠습니다.
df_jeju_shp=df_jeju_shp.set_index("bsn_sector_big_nm")
# 제주특별자치도 데이터셋의 인덱스를 새로 잡아 줍니다.
df_ansan_shp=df_ansan_shp.set_index("bsn_sector_big_nm")
# 안산시의 셋이터셋의 인덱스를 새로 잡아 줍니다.
df_city_shp_rate=pd.merge(df_jeju_shp,df_ansan_shp[['count(*)']],on='bsn_sector_big_nm', right_index=True)
# 두 데이터셋을 업종대분류명을 기준으로 merge 합니다.
df_city_shp_rate
# 합쳐진 데이터를 확인 합니다.
27. 합쳐진 데이터셋을 이용해서 그래프를 그려줍니다.
ax=df_city_shp_rate.sort_values(by='count(*)_x', ascending=False).plot(kind='bar', title='상권분석', figsize=(12, 8), legend=True, fontsize=12)
ax.set_xlabel('시도명', fontsize=12) # x축 정보 표시
ax.set_ylabel('count', fontsize=12) # y축 정보 표시
ax.legend(['제주특별자치시', '안산시'], fontsize=12) 
인구수가 거의 비슷한 도시의 업종별 상가수입니다. 관광도시인 제주특별자치시는 음식, 소매, 숙박업소가 안산시에 비해 많이 있는 것을 확인할 수 있습니다. 특히 숙박의 경우 훨씬 많이 있는 것으로 보입니다. 반대로 의료, 관광/여가/오락, 부동산쪽은 안산시에 더 많이 있는것으로 보입니다. 이 상권 분석 그래프만으로도 두 도시의 특색을 알 수 있습니다.
이것으로 상가(상권) 데이터로 간단하게 데이터 분석을 해보았습니다. 서론에 이야기했듯이 너무나 간단한 지표로 분석해본 실습이었습니다. 상관계수 등 좀 더 고급진(?) 분석을 다음 편에 해보도록 하겠습니다. 다른 좋은 방법이 있으시거나, 궁금하신 점이 있으신 분들은 댓글 남겨주시면 감사하겠습니다.
오늘은 여기까지~!! 감사합니다.
by.sTricky
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| 파이썬 상가(상권)데이터를 이용해서 내 주변 동네 약국 위치 분석 feat.코로나19 마스크 약국 (12) | 2020.03.05 |
|---|---|
| 파이썬 에러 pip upgrade fail, 'NoneType' object has no attribute 'bytes' (0) | 2020.03.03 |
| 파이썬 삽입정렬 알고리즘 Insertionsort #8 (2) | 2020.02.27 |
| 파이썬 순차탐색 알고리즘 sequential search #7 (5) | 2020.02.25 |
| [python_상가(상권)정보DB가지고놀기]공공데이터포털 에서 상가(상권)정보DB 다운 받아 DB에 insert 하기 (4) | 2020.02.24 |



