#[python 데이터분석]파이썬으로 점심식사, 교과목 이수, 부모학력, 인종에 따른 시험 성적 데이터 분석 하기 feat.seaborn.catplot
안녕하세요.
파이썬으로 데이터분석 시간을 오랫만에 가져봅니다.
오늘은 캐글에 있는 데이터중 "Students Performance in Exams" 이라는 데이터셋을 가지고 시험 성적 데이터를 분석해 보겠습니다.
우선 데이터셋 링크는 아래와 같습니다.
https://www.kaggle.com/spscientist/students-performance-in-exams
Students Performance in Exams
Marks secured by the students in various subjects
www.kaggle.com
여기 들어가서 데이터를 다운 받으시면 됩니다.
다운 받은 데이터셋에는 모두 8개의 컬럼이 있고, 총 1,000 row의 데이터를 가지고 있습니다.
컬럼별 데이터 설명은 아래와 같습니다.
gender = 성별
race/ethnicity = 인종/민족성
parental level of education = 부모의 학력
lunch = 점심식사 여부
test preparation course = 시험대비과목 이수여부
math score = 수학 점수
reading score = 읽기 점수
writing score = 쓰기 점수
이 데이터를 이용해서 저는 성별, 인종/민족성, 부모의 학력, 점심식사 여부, 시험대비과목 이수여부 에 관하여 수학, 읽기, 쓰기 점수의 상관관계에 대해서 분석을 해볼까 합니다.
우선 파이썬을 실행하고 필요한 라이브러리들을 import 합니다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns보신바와 같이 pandas, matplotlib, seaborn을 이용하여 분석 및 시각화를 진행 합니다.
그리고 다운받은 데이터를 pd를 이용해서 불러와서 확인 합니다.
df=pd.read_csv("./StudentsPerformance.csv")
df.head()
위와 같이 데이터 불러와서 확인해 보면 분석해야 할 데이터가 보입니다.
그림과 같이 빨간 부분의 데이터를 이용해서 파란표시가된 시험 점수 데이터를 분석 할겁니다.
df.describe()위 명령어로 우선 시험 점수데이터들의 개요를 확인 합니다.

이렇게 시험 점수 데이터들의 count와 평균, 표준편차, 각각의 분위 데이터가 어떻게 들어 있는지 확인이 됩니다.
첫번째 분석 대상은 시험 과목별 점수의 상관관계 입니다. 예를들어 각 학생별 수학점수별 쓰기/읽기 점수, 반대로 쓰기점수 별 수학/읽기 점수가 각각 어떤지를 확인 해볼겁니다.
plt.style.use('dark_background')
sns.set(style="darkgrid",palette="bright", font_scale=1.5)
sns.pairplot(df[['math score','reading score','writing score']], height=4)이렇게 소스를 작성해서 넣습니다. 여기에서 pairplot은 상관관계를 알려주는 그래프를 그려줍니다. 각 시험 과목별 상관관계를 알 수 있겠죠?
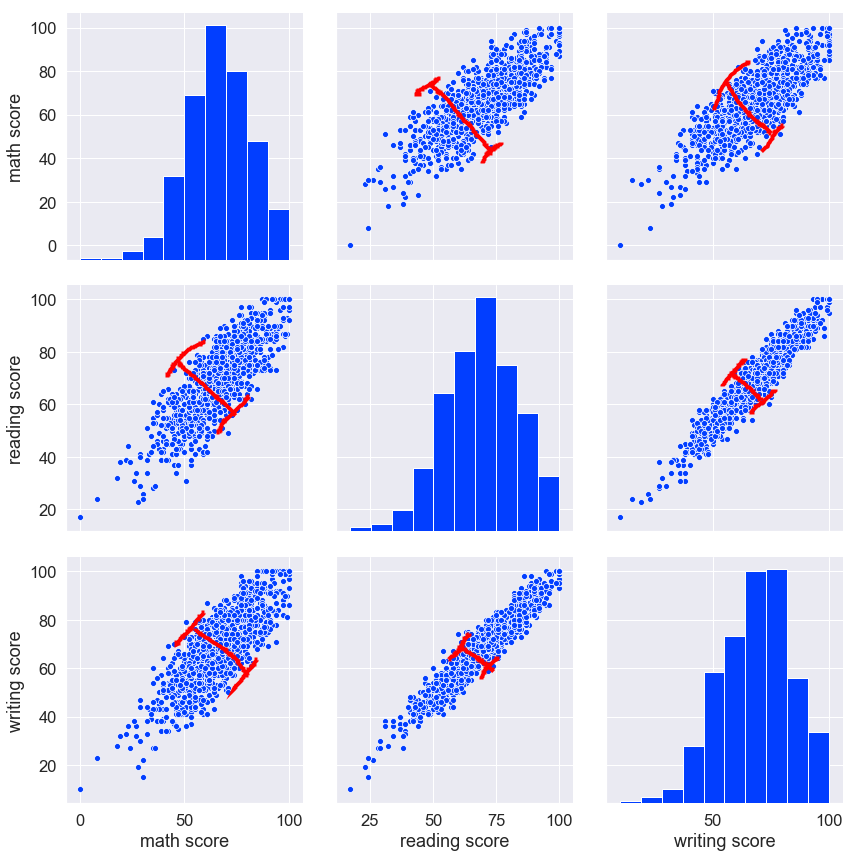
위와 같은 결과가 나옵니다.
첫번째 열을 보시면 아래 math score (수학 점수)가 있는데, 첫번째 열에 있는 3개의 그래프중 가장 위의 막대그래프는 수학 점수별 학생수를 표시한것 입니다.
아래 점으로 되어있는 분포 그래프가 보이는데, 여기서 주목하셔야 할 부분은 바로 빨간선으로 표시된 분포도의 두깨입니다.
저 두깨가 넓을수록 수학 점수와는 상관관계가 많지 않다는걸 의미 합니다. 반대로 좁다면, 상관관계가 많은것이 겠죠?
설명을 덧붙이면 수학점수가 높다고 하여 읽기나 쓰기점수가 높다는 상관관계를 가졌다 볼 수 없다는것 입니다.
중간에 있는 두번째 열은 읽기 점수 인데, 가장위에 있는 수학점수와 읽기점수의 상관관계 역시 많다고 볼 수 없겠죠? 하지만 두번째 열 가장 아래에 있는 쓰기점수의 분포 그래프는 매우 좁습니다. 이것은 읽기 점수가 높은 아이들이 쓰기점수도 높다, 반대로 읽기점수가 낮은 아이들은 쓰기 점수도 낮은 상관관계를 가졌다라고 해석 됩니다.
자, 이젠 두번째 분석을 해보겠습니다. 점심을 먹은 학생과 안먹은 학생들의 시험 점수를 비교해 보겠습니다.
지금 점수가 수학, 읽기, 쓰기 이렇게 3가지가 되니, 분석의 편의를 위해서 세 과목의 평균점수를 구하여 데이터셋에 average_score 라는 컬럼을 만들어 넣어 보겠습니다.
def average_score(dt):
return (dt['math score']+dt['reading score']+dt['writing score'])/3
df['average score'] = df.apply(average_score, axis=1)
df.head()이렇게 코딩하여 데이터셋을 확인해보면 아래와 같이 average_score 가 추가된것을 확인 할 수 있습니다.

그럼 점심식사여부와 평균점수의 상관관계를 알아보는 소스를 입력합니다.
sns.catplot(x='lunch', y='average score', hue='gender', kind='boxen', data=df, height=10, palette=sns.color_palette(['red', 'blue']))
plt.title('average score')그 결과를 볼까요?

그래프를 보면 우선, 여자는 빨간색, 남자는 파란색 막대 그래프로 표현 되어 있으며, 좌측의 한 그룹은 점심을 먹을 남,녀 학생의 평균 점수 분포, 우측의 한 셋은 점심을 먹지 않았거나 조금만 먹은 학생의 평균 점수 분포 입니다.
평균적으로 보았을때 점심 식사를 충분히 한 학생들의 점수가 높다는것을 확인 할 수 있습니다.
더불어 우측에 점심식사를 하지 않은 그룹을 보면 여학생의 경우 점수가 낮은방향으로 쭉 떨어져 있는것을 볼 수 있습니다. 점심식사를 하지않으면 최하위 성적을 거둘 가능성이 있다는것을 보여주는 그래프 입니다.
내친김에 평균 점수가 아니라 과목별 점수 분포도 똑같이 확인해 보겠습니다.
sns.catplot(x='lunch', y='math score', hue='gender', kind='boxen', data=df, height=10, palette=sns.color_palette(['red', 'blue']))
plt.title('math')
sns.catplot(x='lunch', y='reading score', hue='gender', kind='boxen', data=df, height=10, palette=sns.color_palette(['red', 'blue']))
plt.title('reading')
sns.catplot(x='lunch', y='writing score', hue='gender', kind='boxen', data=df, height=10, palette=sns.color_palette(['red', 'blue']))
plt.title('writing')


이렇게 과목별로도 확인해 보았습니다.
평균점수에서 설명한것 처럼 평균 점수가 과목별로도 드러나는것을 확인 할 수 있습니다.
세번째 분석할 항목은 test preparation course (시험대비과목 이수여부) 입니다.
시험대비과목을 이수한 그룹과 그렇지 않은 그룹의 성적을 확인 해보겠습니다.
이번 분석에서는 성별 구분을 제외하고 분석 하도록 하겠습니다.
sns.catplot(x='test preparation course', y='average score', kind='boxen', data=df, height=10, palette=sns.color_palette(['red', 'blue']))
plt.title('average')이렇게 파이썬 코드를 입력하고 나면 아래와 같은 그래프를 볼 수 있습니다.
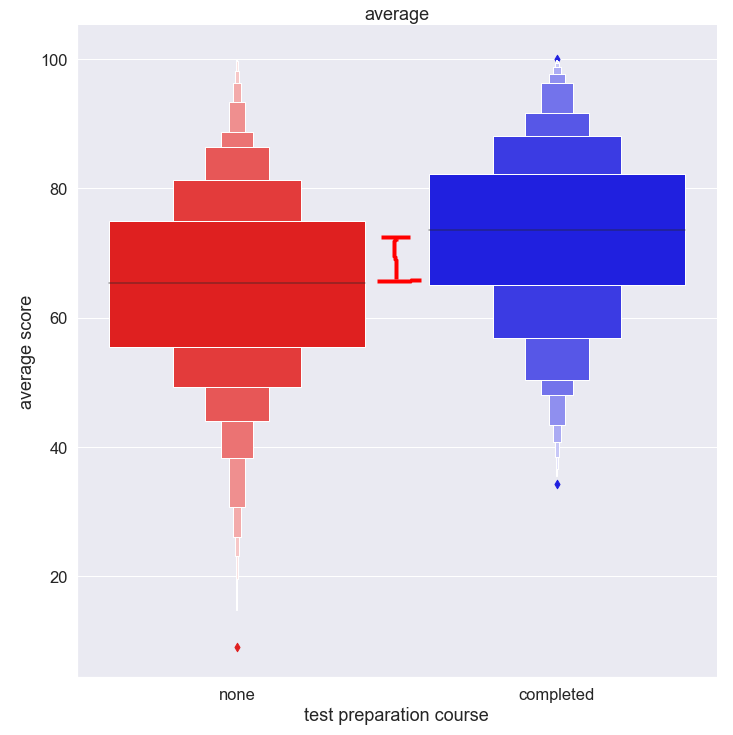
빨간 막대는 시험대비과목을 이수 하지 않은 그룹이고, 파란 막대는 이수한 그룹입니다.
당연하게도? 두 그룹간의 점수 차이는 분명하게 존재 합니다.
너무나 당연한 결과라 설명이 필요 없을듯 합니다.
다음, 네번째 분석은 parental level of education(부모의 학력) 에 따른 성적 분석 입니다.
sns.catplot(x='parental level of education', y='average score', kind='boxen', data=df, height=14)
plt.title('average')
plt.legend(loc='lower right')파이썬 코드를 입력을 하고나면,

부모의 학력에 따라 학생들의 성적 분포도를 확인 할 수 있습니다.
약간의 높낮이가 있으나 아주 큰 차이를 보이는것 같지는 않습니다. 그래도 미세하게나마 석사이상의 학력을 가진 부모의 학생들이 평균점수가 가장 높은걸 알 수 있습니다.
마지막 데이터 분석은 race/ethnicity(인종/민족성) 에 따른 학생들의 성적 분포 입니다.
캐글에 있는 데이터는 아무래도 인종차별등의 문제때문인지 인종에 대해 정확한 표기보단 group A,B,C.. 와 같이 나누어 표기해 두었음을 미리 양해 드립니다.
sns.catplot(x='race/ethnicity', y='average score', kind='boxen', data=df, height=14)
plt.title('average')
plt.legend(loc='lower right')역시 같은방법으로 파이썬 코드를 입력하고 나면 아래와 같이 그래프가 나옵니다.

인종/민족성에 따라 점수가 다름을 확인 할 수 있습니다.
어떤 인종/민족성 인지 모르겠으나, 초록색 그래프가 가장 낮고, 보라색이 가장 높음을 알 수 있습니다.
오늘은 이렇게 seaborn.catplot 을 이용해서 데이터 분석을 진행해 보았습니다.
아마 제 블로그에 있는 데이터 분석 실습을 한번이라도 보신분들은 아시겠지만.. 그래도 조금씩 실력이 늘고 있는것 같아서 전 매우 뿌듯합니다.
여러분들도 혹시 저처럼 시작하시는 분들이 있으면 예제를 보고 하나씩 따라하면서 함께 실력을 키워보시길 바라겠습니다.
오늘 분석 실습과 관련하여 문의 사항이 있으시면 댓글 부탁드립니다.
오늘 시험성적 데이터 분석은 아래 youtube 실습예제를 참고로 약간 변형하여 진행 했습니다.
감사합니다!
by.sTricky
'DB엔지니어가 공부하는 python' 카테고리의 다른 글
| [python 데이터분석]파이썬으로 로또 당첨번호 및 당첨금 데이터 분석 하기 feat.pandas, pyplot (26) | 2020.02.13 |
|---|---|
| 파이썬 재귀호출 알고리즘 하노이의 탑 옮기기 #6 (4) | 2020.02.11 |
| 파이썬 재귀호출 알고리즘 팩토리얼 구하기 #5 (0) | 2020.02.05 |
| 파이썬 리스트 알고리즘 동명이인을 찾아라!! #4 (2) | 2020.01.31 |
| [python_주소DB가지고놀기] 주소DB 월변동분 적용 하기 #4 (0) | 2020.01.31 |



