네이버카페 파이썬 크롤링 데이터 간단한 분석 및 워드클라우드 예제
네이버카페 파이썬 크롤링 데이터 간단한 분석 및 워드클라우드 예제

안녕하세요.
일전에 제가 자주 활동하는 한 카페의 자유게시판과 나눔게시판 데이터를 파이썬으로 크롤링하였습니다.
데이터를 모았으니, 이젠 분석을 해봐야겠죠?
분석이래봐야 뭐 대단한건 없습니다. 그냥 통계정도를 뽑아보고 게시글의 제목이나, 본문의 텍스트를 이용하여 워드클라우드 실습도 해보도록 하겠습니다.
참고로, 파이썬으로 네이버 카페 크롤링한 소스 및 자세한 내용은 아래 링크에서 확인 하실수 있습니다.
2021.06.15 - [DB엔지니어가 공부하는 python] - [파이썬]네이버 카페 게시판 크롤링 웹 스크래핑 2021년 버전
[파이썬]네이버 카페 게시판 크롤링 웹 스크래핑 2021년 버전
[파이썬]네이버 카페 게시판 제목, 본문, 작성자, 글번호 웹 스크래핑 2021년 버전 안녕하세요. 한 2년여전에 네이버 카페 스크래핑을 할 일이 있어서 했었고, 이번에 다시 하는데, 안되더라구요.
stricky.tistory.com
파이썬 라이브러리 import 및 DB 커넥션
우선, vscode를 실행하고, 저는 주피터 노트북을 사용하여 코드를 작성 했습니다.
먼저 아래와 같이 라이브러리 추가하고, DB 커넥션 하겠습니다.
import folium
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
#한글글꼴 지정
plt.rc('font', family='NanumGothic')
print(plt.rcParams['font.family'])
# db connect
conn = pymysql.connect(host='121.xxx.xxx.148', user = 'db_account', password='password', db = 'keyword',charset = 'utf8')
curs = conn.cursor(pymysql.cursors.DictCursor)
나눔게시판 데이터 확인
자, 그럼 나눔게시판에서 크롤링한 데이터에서 작성자 별로 글을 몇개가 있는지 확인 해보도록 하겠습니다. DB에 커넥트하여 SQL을 실행하고, 그 결과를 dataframe에 저장 하겠습니다. 마지막으로 출력까지 합니다.
# 나눔 글쓴이별 수
sql = "select writer, count(*) as cnt from jau_2021_ori where chk = 'N' group by writer order by count(*) desc"
curs.execute(sql)
nanum_user = curs.fetchall()
df_nanum = pd.DataFrame(data=nanum_user)
print(df_nanum)아래와 같이 출력이 되었습니다.

토탈 325명이 나눔게시판에 글을 쓰셨네요.
중간에 대화명을 바꾸신분도 계신터이니, 300명이 안되는 분이 여태까지 나눔에 참여 하신걸로 볼 수 있겠습니다.
여기서 상위 20위까지의 데이터를 가지고 그래프를 그려보도록 하겠습니다.
전체 다 그리기엔 사람이 너무 많습니다.
df_nanum = df_nanum[df_nanum.index < 20]위 코드를 이용해서 index번호가 20안쪽 까지만 남기고 나머지는 df_nanum에서 삭제를 합니다.
그리고 아래 코드로 그래프를 그립니다.
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 50) #x축 조절
sns.barplot(
data = df_nanum.sort_values(by='cnt', ascending=False),
x = "writer",
y = "cnt"
)
plt.show()아래와 같은 이쁜 그래프가 나옵니다.

다음은 나눔게시판내 나눔글 추이를 년도별로 보도록 하겠습니다.
SQL을 작성해서 파이썬 코드에 적용을 하고, 그래프까지 그리겠습니다.
#년도별 나눔 추이
sql = "select date_format(upload_date, '%Y') as year , count(*) as cnt from clubrav4.jau_2021_ori where chk = 'N' group by date_format(upload_date, '%Y') order by year"
curs.execute(sql)
nanum_year = curs.fetchall()
df_nanum_year = pd.DataFrame(data=nanum_year)
#그래프
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 50) #x축 조절
sns.barplot(
data = df_nanum_year.sort_values(by='year', ascending=True),
x = "year",
y = "cnt"
)
plt.show()
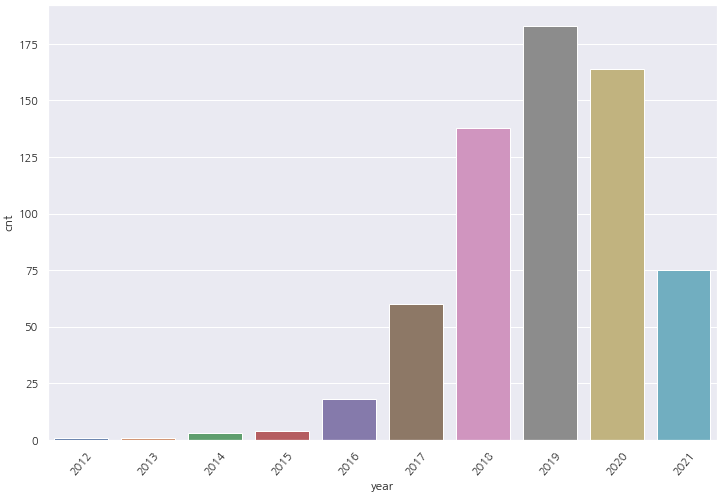
2012년을 기점으로 나눔게시글이 점점 상승 하고 있는것을 확인 할 수 있습니다.
2019년 대비하여 2020년에 소폭 줄어들었지만, 2021년에 상반기 현재 약 75건 정도 나눔게시글이 나오고 있네요.
시공/장착/정비/수리 팁 공유 게시판 분석
다음은 시공/장착/정비/수리 팁을 공유 하신 분들에 대한 분석을 해보겠습니다.
나눔게시판과 마찬가지로, 우선 많은 글을 공유 해주신분들 찾아볼께요. 세대별로 게시판이 나뉘어 있는데, 4세대, 5세대 각각 뽑아 보도록 하겠습니다. 먼저 4세대입니다.
# 세대별 시공/장착/정비/수리 팁
sql = "select writer, count(*) as cnt from clubrav4.jau_2021_ori where chk = '4' group by writer order by count(*) desc"
curs.execute(sql)
sg_user4 = curs.fetchall()
df_sg_user4 = pd.DataFrame(data=sg_user4)
print(df_sg_user4)
전체 1168명이 참여를 해주셨었네요. 다들 감사드립니다. 좋은팁 많이 공유 해주셔서..ㅎㅎ
이중에서 상위 20명을 뽑아 그래프로 나타내 보겠습니다.
# 상위 20명 추출
df_sg_user4 = df_sg_user4[df_sg_user4.index < 20]
# 그래프 그리기
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 50) #x축 조절
sns.barplot(
data = df_sg_user4.sort_values(by='cnt', ascending=False),
x = "writer",
y = "cnt"
)
plt.show()
위와 같이 나타낼 수 있습니다.
5세대에 대해서도 똑같이 작업을 해보도록 하겠습니다.
# 세대별 시공/장착/정비/수리 팁
sql = "select writer, count(*) as cnt from clubrav4.jau_2021_ori where chk = '5' group by writer order by count(*) desc"
curs.execute(sql)
sg_user5 = curs.fetchall()
df_sg_user5 = pd.DataFrame(data=sg_user5)
print(df_sg_user5)
5세대는 총 344명이 참여 해주셨군요! 마찬가지로 감사드립니다.

1등이신분이 압도적이신걸 확인 할수가 있네요.
이렇게 많은분들이 팁을 공유 해주시고 있습니다.
목격담 게시판 분석
다음은 목격담 게시판 분석을 하겠습니다.
위와 같은 방법으로 진행을 하겠습니다.
코드는 아래와 같습니다.
# 목격담 게시판
sql = "select writer, count(*) as cnt from clubrav4.jau_2021_ori where chk = 'M' group by writer order by count(*) desc"
curs.execute(sql)
mok_user = curs.fetchall()
df_mok_user = pd.DataFrame(data=mok_user)
print(df_mok_user)
그래프 코드도 위와 거의 동일 합니다.
참고만 하세요.
plt.figure(figsize=(12,8)) #size 조절
plt.xticks(rotation = 50) #x축 조절
sns.barplot(
data = df_mok_user.sort_values(by='cnt', ascending=False),
x = "writer",
y = "cnt"
)
plt.show()
자유게시판 분석
마지막으로 자유게시판 분석 입니다.
먼저 위와 마찬가지로 글쓴이들별 발행수를 확인 해보겠습니다.
참고로 자유게시판은 글수가 많은 관계로 2020년 1월 1일 이후부터 지금까지 약 1년 6개월간의 데이터로 분석을 진행 하겠습니다.
# 자유게시판
sql = "select writer, count(*) as cnt from clubrav4.jau_2021_ori where chk = 'J' group by writer order by count(*) desc"
curs.execute(sql)
jau_user = curs.fetchall()
df_jau_user = pd.DataFrame(data=jau_user)
print(df_jau_user)
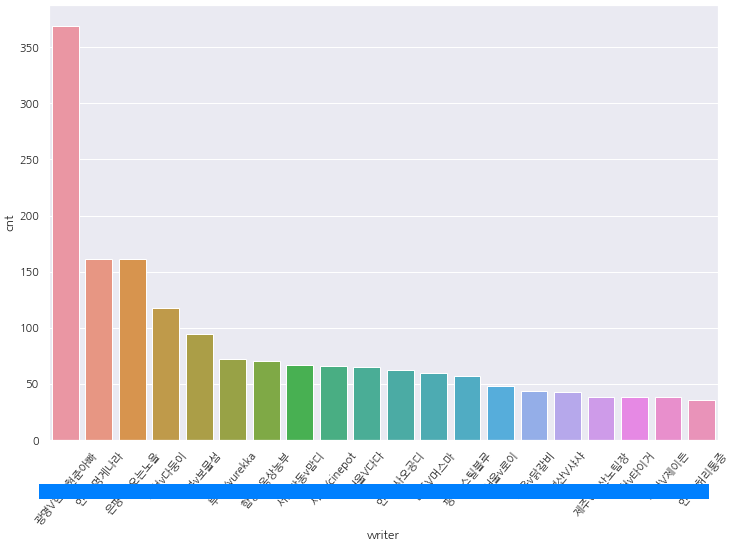
1년 6개월치이지만 글 작성자수가 약 1249명이나 됩니다.
어마어마 하군요. 참고로 전체 글 수는 6170건 입니다.
상위 20명의 그래프도 그려보도록 하겠습니다.
이번에는 카페 회원들이 어떤요일에 글을 많이 썼는지를 확인 해보도록 하겠습니다.
코드는 아래와 같이 작성 하면 됩니다.
#요일별 자유게시판 게시글 수
sql = "select CASE week_num WHEN '1' THEN '일요일' WHEN '2' THEN '월요일' WHEN '3' THEN '화요일' WHEN '4' THEN '수요일' WHEN '5' THEN '목요일' WHEN '6' THEN '금요일' WHEN '7' THEN '토요일' END AS weekd, cnt from (select DAYOFWEEK(upload_date) as week_num, count(*) as cnt from jau_2021_ori where chk = 'J' group by week_num) a group by week_num order by cnt desc"
curs.execute(sql)
jau_week_user = curs.fetchall()
df_jau_week_user = pd.DataFrame(data=jau_week_user)
print(df_jau_week_user)이렇게 dataframe을 먼저 만들어줍니다.
아래와 같이 잘 출력이 되었네요.
mysql에서 날짜 데이터의 요일을 출력하는 방법이 몇가지 있지만 여기서는 dayofweek 함수를 사용했고, 1,2,3... 이렇게 나오는 출력값을 case when 함수로 한글로 바꾸어 출력 하도록 했습니다.

이걸 이용해서 이번에는 원그래프로 표현 해보겠습니다.
코드는 아래와 같습니다.
df_jau_week_user=df_jau_week_user.set_index("weekd")
# 새로운 인덱스 지정
group_colors = ['yellowgreen', 'lightskyblue', 'lightcoral', 'green', 'red', 'gray', 'blue'] # 색상지정
group_explodes = (0, 0, 0, 0, 0.2, 0, 0) # 제일 많은 값의 슬라이스를 분리하여 강조
plot = df_jau_week_user.plot.pie(subplots=True, y='cnt', figsize=(15, 15),shadow=True,startangle=150,explode = group_explodes,colors=group_colors,autopct='%3.2f%%')
# pie 그래프 작성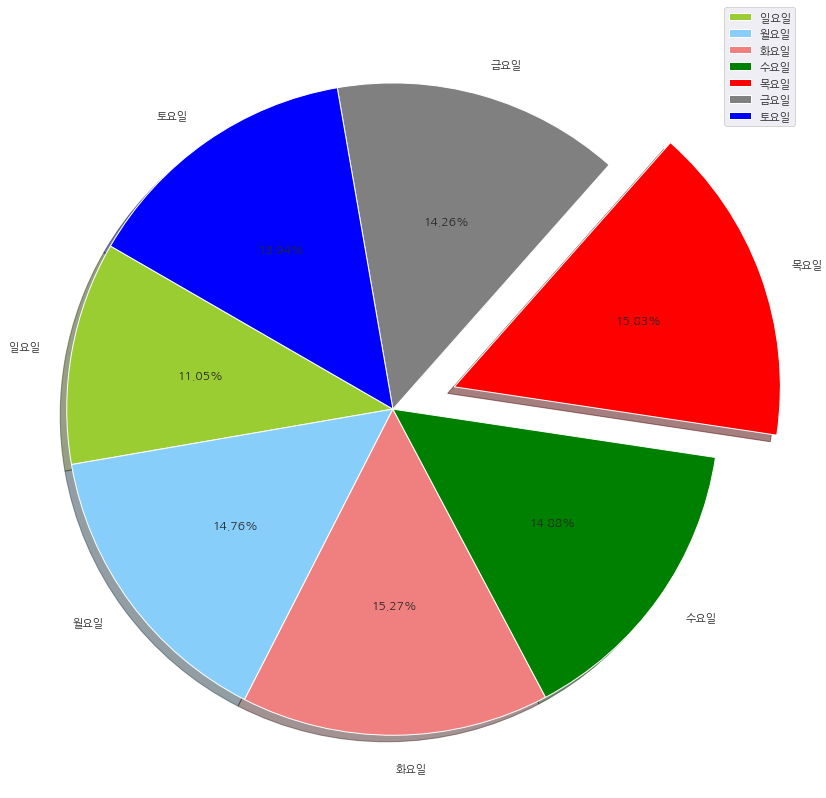
목요일에 게시글을 가장 많이 쓰셨네요.
토요일, 일요일이 역시.. 가정에 충실하시느라 게시글이 적은편 이구요.
자유게시판 워드클라우드
자유게시판의 데이터들을 가지고 wordcloud 기법으로 표현해 보겠습니다.
우선, 이번에 워드클라우드는 지난번과는 다르게 파이썬으로 하지 않고, 파이썬에서 데이터들을 형태소 분리를 하여 명사들만 추출하고, 카운팅하고, 정리하여 DataFrame으로 csv로 저장한 다음 wordCloud 서비스를 해주는 웹사이트에서 이미지를 생성하는 방식으로 해보겠습니다.
지난번 파이썬 워드클라우드 생성 소스를 보시고 싶으신분들은 아래 링크로 가서 확인하시면 됩니다.
[python] 파이썬으로 네이버 카페 게시판 크롤링 & 워드 클라우드 실습 하기! (feat.konlpy.Twitter)
안녕하세요. 데이터 분석의 첫걸음으로 워드 클라우드를 분석하기 위해 제가 가입해 활동하고 있는 자동차 네이버 카페의 자유게시판을 크롤링했습니다. 지난 2019년 작성된 자동차 카페 내 자
stricky.tistory.com
이번에 워드클라우드를 생성할 사이트는 아래 사이트입니다.
필요하신분들은 아래 사이트로 가셔서 서비스를 이용 하시면 됩니다.
워드클라우드
워드클라우드 워클생성기 워클 단어구름 한글 워드클라우드 구름단어 글자구름 구름글자 태그클라우드 워드클라우드 태그구름 랜덤이미지 블로그이미지 페이스북이미지
wordcloud.kr
우선, DB에 모아둔 자유게시판의 게시글과 제목들을 하나의 텍스트파일로 합쳐줍니다.
그리고 그 파일을 가지고 아래 파이썬 코드로 실행을 합니다.
from konlpy.tag import Twitter
from collections import Counter
import pandas as pd
file = open("D:/jau_2021_ori_cont.txt", "r", encoding='UTF8')
lists = file.readlines()
file.close()
twitter = Twitter()
morphs = []
for sentence in lists:
morphs.append(twitter.pos(sentence))
print(morphs)
noun_adj_adv_list=[]
for sentence in morphs :
for word, tag in sentence :
if tag in ['Noun'] and ("것" not in word) and ("더" not in word) and ("정도" not in word) and ("땐" not in word) and ("브" not in word) and ("도" not in word) and ("치" not in word) and ("때" not in word) and ("위" not in word) and ("앞" not in word) and ("저" not in word) and ("등" not in word) and ("전" not in word) and ("요" not in word) and ("분" not in word) and ("시" not in word) and ("카" not in word) and ("너" not in word) and ("및" not in word) and ("이" not in word) and ("거" not in word) and ("좀" not in word) and ("제" not in word) and ("후" not in word) and ("비" not in word) and ("내" not in word)and ("나" not in word)and ("수"not in word) and("게"not in word)and("말"not in word):
noun_adj_adv_list.append(word)
print(noun_adj_adv_list)
count = Counter(noun_adj_adv_list)
words = dict(count.most_common())
print(words)
words_df = pd.DataFrame.from_dict(words, orient='index')
print(words_df)
words_df.to_csv("rav4_jau_words_conts.csv", mode='w')제가 아무래도 데이터 엔지니어이고, 개발자가 아니다보니 흔히들 이야기하시는 파이써닉한 코드를 작성 하진 못합니다. 그냥 되는데로 코드를 작성하기때문에..ㅎㅎ 일부 코딩을 잘하시는 분들이 볼까 무서운 코드네요.
각설하고, 이 코드들이 하는 역할은 앞에서 저장한 텍스트 파일을 읽어와서 konlpy라는 라이브러리를 이용하여 문장 단위로 읽어와 형태소를 분석 합니다. 쉽게 이야기해서, 이건 명사, 이건 부사, 이건 형용사.. 이렇게 나누는건데 100% 정확하지는 않습니다만 워드클라우드를 하는데 있어서는 부족함이 없다고 생각이 듭니다.
그렇게 형태소 분석을 하고, 명사만 추출을 하여 출현 횟수를 저장합니다. 그리고 다시 csv 파일로 결과를 저장해주는 역할을 하게 됩니다. 자, 그럼 이젠 워드클라우드를 해주는 사이트로 가서 한번 만들어 볼께요.
해당사이트로 접속하여 아래와 같이 설정을 하고, 텍스트파일을 10,000글자 이하로 넣어주시면 됩니다.

쉽고 간단하게 이용 할 수 있네요. 이렇게 해서 나온 이미지를 보겠습니다. 우선 자유게시판 제목으로 워드클라우드를 생성한 모습 입니다.

다음은 자유게시판의 컨텐츠 내용으로 만든 워드클라우드 입니다.
어떻게 나왔는지 한번 볼까요?

자, 이렇게 오늘은 해야지 해야지 했던 카페 크롤링 및 워드클라우드, 데이터 통계분석을 해보았습니다.
이번 한주도 여러분들 잘 마무리 하시고, 항상 건강하시길 바랍니다.
감사합니다!!
by.sTricky