[python 데이터 분석 실습] 코로나 19 2021 현재 시점 분석하기 1편
코로나 19 2021 현재 시점 python으로 데이터 분석하기

안녕하세요.
파이썬 데이터 분석 실습 쉽게 따라해보기~ 이번 시간은 코로나 19의 2021년 현재 상황 분석 하기 입니다.
우리 세상을 뒤덮고, 일상생활을 아주~ 힘들게 하고 있는 이 코로나 19의 현 시점 상황에 대해서, 데이터를 이용하여 알아보도록 하겠습니다.
첫번째 시간으로 우선 데이터 가지고 오고, 정리하는 시간을 가지도록 하겠습니다.
그럼 바로 시작 해보도록 하겠습니다.
Let's Go~!!!
Covid 19 데이터 다운로드
아래 코드를 이용하여 covid19 데이터 분석을 위한 csv 데이터를 다운로드 하도록 하겠습니다.
import os
import requests
for filename in ['time_series_covid19_confirmed_global.csv',
'time_series_covid19_deaths_global.csv',
'time_series_covid19_recovered_global.csv',
'time_series_covid19_confirmed_US.csv',
'time_series_covid19_deaths_US.csv']:
print(f'Downloading {filename}')
url = f'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/{filename}'
myfile = requests.get(url)
open(filename, 'wb').write(myfile.content)코드를 실행하면 아래와 같이 5개의 csv 파일이 다운로드 됩니다.

데이터 컬럼명 변경
자, 그럼 위 파일중 하나(time_series_covid19_confirmed_global.csv)를 열어보겠습니다. 그럼 아래와 같은 데이터가 보이는데, 컬럼명을 보시면 날짜형식이 / 와 함께 들어가 있는것을 확인 할 수 있습니다. 이러한 날짜형식을 우리가 알아보기 쉽게 좀 변경을 해볼께요. 아래와 코드로 말이죠.

from datetime import datetime
import pandas as pd
def _convert_date_str(df):
try:
df.columns = list(df.columns[:4]) + [datetime.strptime(d, "%m/%d/%y").date().strftime("%Y-%m-%d") for d in df.columns[4:]]
except:
print('_convert_date_str failed with %y, try %Y')
df.columns = list(df.columns[:4]) + [datetime.strptime(d, "%m/%d/%Y").date().strftime("%Y-%m-%d") for d in df.columns[4:]]
confirmed_global_df = pd.read_csv('time_series_covid19_confirmed_global.csv')
_convert_date_str(confirmed_global_df)
deaths_global_df = pd.read_csv('time_series_covid19_deaths_global.csv')
_convert_date_str(deaths_global_df)
recovered_global_df = pd.read_csv('time_series_covid19_recovered_global.csv')
_convert_date_str(recovered_global_df)위 코드를 보시면 아시겠지만 _convert_date_str 라는 함수를 생성하여 다운로드 받은 파일중 3개의 파일의 컬럼 형식을 변경 하도록 합니다. 그리고 나서 데이터를 확인하면 변경 된 것을 확인 할 수 있죠.
deaths_global_df
데이터 클랜징 작업
다음은 데이터 클랜징 작업 입니다. 아래 코드는 일부 음수가 있는 값들과 cruise ship의 감염자 수치가 잘못 들어간것들을 정제 합니다.
import numpy as np
removed_states = "Recovered|Grand Princess|Diamond Princess"
removed_countries = "US|The West Bank and Gaza"
confirmed_global_df.rename(columns={"Province/State": "Province_State", "Country/Region": "Country_Region"}, inplace=True)
deaths_global_df.rename(columns={"Province/State": "Province_State", "Country/Region": "Country_Region"}, inplace=True)
recovered_global_df.rename(columns={"Province/State": "Province_State", "Country/Region": "Country_Region"}, inplace=True)
confirmed_global_df = confirmed_global_df[~confirmed_global_df["Province_State"].replace(np.nan, "nan").str.match(removed_states)]
deaths_global_df = deaths_global_df[~deaths_global_df["Province_State"].replace(np.nan, "nan").str.match(removed_states)]
recovered_global_df = recovered_global_df[~recovered_global_df["Province_State"].replace(np.nan, "nan").str.match(removed_states)]
confirmed_global_df = confirmed_global_df[~confirmed_global_df["Country_Region"].replace(np.nan, "nan").str.match(removed_countries)]
deaths_global_df = deaths_global_df[~deaths_global_df["Country_Region"].replace(np.nan, "nan").str.match(removed_countries)]
recovered_global_df = recovered_global_df[~recovered_global_df["Country_Region"].replace(np.nan, "nan").str.match(removed_countries)]다음 과정은 Afghanistan 데이터를 예를 들어보면 하나의 Afghanistan 데이터에 각 날짜컬럼별로 데이터가 들어가 있던것을 열로 바꿔주는 코드를 작성 해보겠습니다. 아래 그림을 보시면 이해가 되시리라 생각합니다.

confirmed_global_melt_df = confirmed_global_df.melt(
id_vars=['Country_Region', 'Province_State', 'Lat', 'Long'], value_vars=confirmed_global_df.columns[4:], var_name='Date', value_name='ConfirmedCases')
deaths_global_melt_df = deaths_global_df.melt(
id_vars=['Country_Region', 'Province_State', 'Lat', 'Long'], value_vars=confirmed_global_df.columns[4:], var_name='Date', value_name='Deaths')
recovered_global_melt_df = deaths_global_df.melt(
id_vars=['Country_Region', 'Province_State', 'Lat', 'Long'], value_vars=confirmed_global_df.columns[4:], var_name='Date', value_name='Recovered')confirmed_global_df, deaths_global_df, deaths_global_df 이 3개의 df를 각각 melt 함수를 사용하여 confirmed_global_melt_df, deaths_global_melt_df, recovered_global_melt_df 각각 다른 df로 만들어 주겠습니다. 그랬더니 confirmed_global_df를 기준으로 기존 271개의 entries가 116,801개로 늘어난것을 확인 할 수 있습니다.
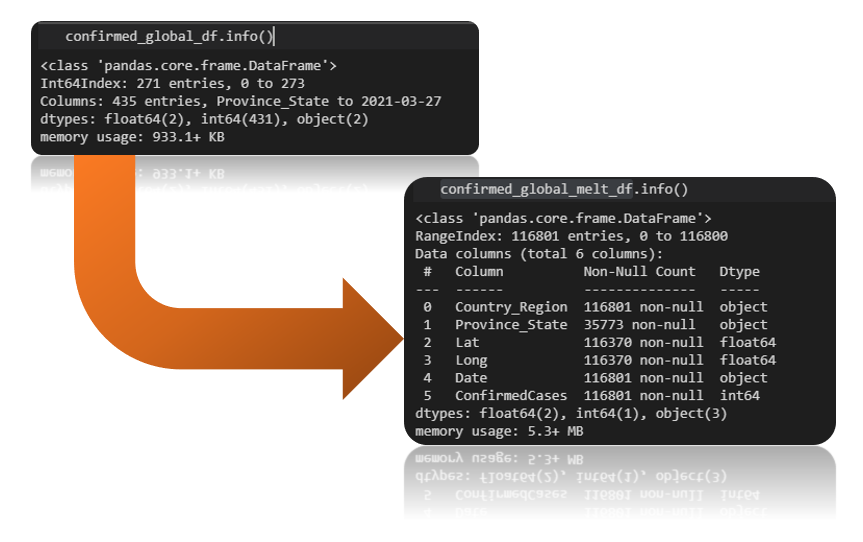
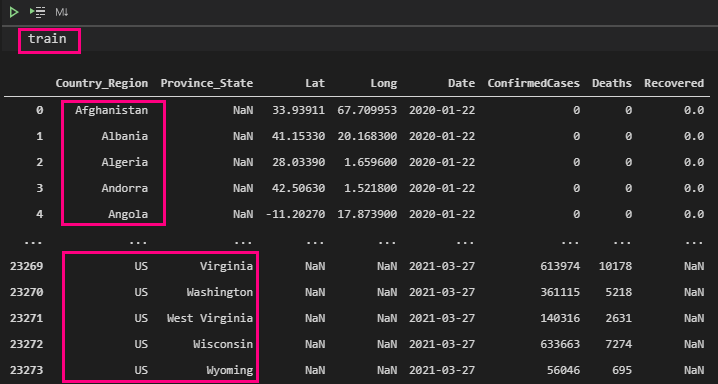
다음은, train이라는 이름으로 confirmed_global_melt_df, deaths_global_melt_df, recovered_global_melt_df 각각으로 흩어져 있던 데이터를 하나로 합치는 과정을 진행 합니다. 아래 코드를 참고 하세요.
train = confirmed_global_melt_df.merge(deaths_global_melt_df, on=['Country_Region', 'Province_State', 'Lat', 'Long', 'Date'])
train = train.merge(recovered_global_melt_df, on=['Country_Region', 'Province_State', 'Lat', 'Long', 'Date'])
train그리고 train 데이터셋을 확인 합니다. 아래와 같이 잘 합쳐진것을 확인 할 수 있습니다.

US 데이터 클랜징 작업
지금까지는 미국을 제외한 global 데이터를 가지고 데이터를 준비 했고, 아래 과정은 US 데이터를 가지고 보기좋게 데이터를 정리 해보겠습니다.
global 데이터와 마찬가지로 날짜 컬럼명을 바꾸고, 필요없는 컬럼들을 drop 해줍니다.
('UID', 'iso2', 'iso3', 'code3', 'FIPS', 'Admin2', 'Combined_Key')
confirmed_us_df = pd.read_csv('time_series_covid19_confirmed_US.csv')
deaths_us_df = pd.read_csv('time_series_covid19_deaths_US.csv')
confirmed_us_df.drop(['UID', 'iso2', 'iso3', 'code3', 'FIPS', 'Admin2', 'Combined_Key'], inplace=True, axis=1)
deaths_us_df.drop(['UID', 'iso2', 'iso3', 'code3', 'FIPS', 'Admin2', 'Combined_Key', 'Population'], inplace=True, axis=1)
confirmed_us_df.rename({'Long_': 'Long'}, axis=1, inplace=True)
deaths_us_df.rename({'Long_': 'Long'}, axis=1, inplace=True)
_convert_date_str(confirmed_us_df)
_convert_date_str(deaths_us_df)데이터 클랜징 과정
confirmed_us_df = confirmed_us_df[~confirmed_us_df.Province_State.str.match("Diamond Princess|Grand Princess|Recovered|Northern Mariana Islands|American Samoa")]
deaths_us_df = deaths_us_df[~deaths_us_df.Province_State.str.match("Diamond Princess|Grand Princess|Recovered|Northern Mariana Islands|American Samoa")]일부 데이터 합치기
confirmed_us_df = confirmed_us_df.groupby(['Country_Region', 'Province_State']).sum().reset_index()
deaths_us_df = deaths_us_df.groupby(['Country_Region', 'Province_State']).sum().reset_index()그리고, US 데이터에서는 위도, 경도 데이터를 drop 해줍니다.
confirmed_us_df.drop(['Lat', 'Long'], inplace=True, axis=1)
deaths_us_df.drop(['Lat', 'Long'], inplace=True, axis=1)마지막으로 melt 함수로 unpivot 해주겠습니다. 더불어 train_us를 새롭게 생성 합니다.
confirmed_us_melt_df = confirmed_us_df.melt(
id_vars=['Country_Region', 'Province_State'], value_vars=confirmed_us_df.columns[2:], var_name='Date', value_name='ConfirmedCases')
deaths_us_melt_df = deaths_us_df.melt(
id_vars=['Country_Region', 'Province_State'], value_vars=deaths_us_df.columns[2:], var_name='Date', value_name='Deaths')
train_us = confirmed_us_melt_df.merge(deaths_us_melt_df, on=['Country_Region', 'Province_State', 'Date'])아래와 같이 데이터가 잘 정리된것을 확인 할 수 있습니다.

이젠, global 데이터 train과 train_us 데이터를 합치도록 하겠습니다.
train = pd.concat([train, train_us], axis=0, sort=False)
train_us.rename({'Country_Region': 'country', 'Province_State': 'province', 'Date': 'date', 'ConfirmedCases': 'confirmed', 'Deaths': 'fatalities'}, axis=1, inplace=True)
train_us['country_province'] = train_us['country'].fillna('') + '/' + train_us['province'].fillna('')잘 합쳐졌는지 확인 해보겠습니다 train을 불러오겠습니다.
합쳐진 train 데이터 셋의 컬럼명을 일부 변경 하도록 하겠습니다. 그리고, country_privince 라는 컬럼을 추가 하여 country와 province 값을 구분하여 넣도록 하겠습니다.
train.rename({'Country_Region': 'country', 'Province_State': 'province', 'Id': 'id', 'Date': 'date', 'ConfirmedCases': 'confirmed', 'Deaths': 'fatalities', 'Recovered': 'recovered'}, axis=1, inplace=True)
train['country_province'] = train['country'].fillna('') + '/' + train['province'].fillna('')데이터를 확인 해 보겠습니다.

이렇게 이번 첫번째 시간에는 데이터 분석을 위한 준비를 해보았습니다.
다음시간부터 covid19 데이터셋을 이용한 데이터 분석을 본격적으로 해보겠습니다.
감사합니다.
# 다음편 보러가기 #
2021.04.22 - [Data Science] - [python 데이터 분석 실습] 코로나 19 2021 현재 시점 데이터 시각화 분석하기 2편
[python 데이터 분석 실습] 코로나 19 2021 현재 시점 데이터 시각화 분석하기 2편
[python 데이터 분석 실습] 코로나 19 2021 현재 시점 데이터 시각화 분석하기 2편 파이썬 데이터 분석 코로나19 데이터 분석 실습 두번째 시간 입니다. 1편을 올리고 시간이 좀 늦었습니다. 이번편에
stricky.tistory.com
by.sTricky