[python 데이터분석]파이썬으로 로또 당첨번호 및 당첨금 데이터 분석 하기 feat.pandas, pyplot
[python 데이터분석]파이썬으로 로또 당첨번호 및 당첨금 데이터 분석 하기 feat.pandas, pyplot
안녕하세요.
파이썬 데이터 분석 해보겠습니다.
이번 데이터 분석은 첨으로 온전한 저 스스로 하는 데이터 분석 입니다.
그래서 조금 허접 할 수 있다는 점! 미리 알려드립니다..ㅎㅎ
이번 시간에 하는 분석은 로또 1등 당첨번호중 그 빈도를 추출 하는 것과 당첨금 데이터 추이를 확인 해 보겠습니다.
로또 1등 당첨번호 및 당첨금에 대한 데이터는 이전에 포스팅했던 로또 당첨번호 및 당첨금 데이터 크롤링 한걸 엑셀 파일로 저장 하는 포스팅을 했었는데 거기서 저장 한 데이터를 이용 했습니다.
2020/01/16 - [DB엔지니어가 공부하는 python] - [python] 파이썬으로 역대 로또 당첨번호, 1등 당첨금 수집 후 엑셀,텍스트 파일에 저장 feat.미완성
[python] 파이썬으로 역대 로또 당첨번호, 1등 당첨금 수집 후 엑셀,텍스트 파일에 저장 feat.미완성
안녕하세요. 1일 1공부를 목표로 파이썬을 스터디 하고 있는 8년차 DB엔지니어 sTricky 입니다. 사실 몇일 비었는데.. 쉴려고 쉰건 아니고, 하고싶은 주제를 목표하는만큼 끌어 올리는데 실패해서 늦어졌습니다...
stricky.tistory.com
위 포스팅을 참고 하시면 됩니다.
바로 시작 하겠습니다.
우선 위에서 크롤링한 데이터를 저장 한 엑셀 파일을 불러 옵니다.
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt라이브러리 선언 부터 하구요, pandas와 matplotlib, pyplot 을 선언해 줍니다.
엑셀 파일도 불러오구요~!
df=pd.read_csv("./lotto_number_history.csv")
df.head(50)
이렇게 데이터가 잘 불러져 온것을 확인 할 수 있습니다.
컬럼명에 대해서 설명 드리고 가겠습니다.
seq - 회차
date - 추첨일
sell_amount - 총판매금액
total_reward - 1등당첨금총액
winner_cnt - 1등당첨자수
winner_reward - 1인당1등당첨금액
no1 - 첫번째 번호
no2 - 두번째 번호
no3 - 세번째 번호
no4 - 네번째 번호
no5 - 다섯번째 번호
no6 - 여섯번째 번호
bn - 보너스 번호
이렇게 데이터가 구성 되어 있습니다.
그럼 이젠 총 데이터 요약을 확인 해 보겠습니다.
요약정보로만으로도 많은 정보를 확인 할 수 있습니다.
df.describe()
이렇게 보니, 숫자에 'e+...' 어쩌구 이렇게 나오네요.
데이터가 저렇게 나오면 곤란하니, 아래 명령어로 실수를 다 표시 하도록 변경 합니다.
pd.options.display.float_format = '{:.2f}'.format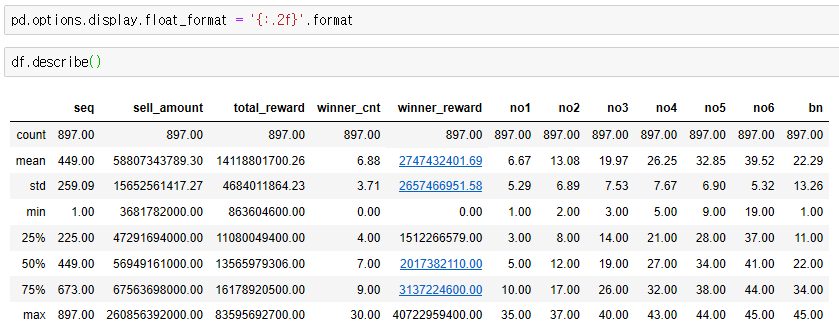
짜잔! 이렇게 숫자가 잘 나오고 있습니다.
하지만 천자리마다 찍히는 , 콤마가 없으니 얼마인지 눈에 한번에 들어오지 않습니다.
해결해 볼께요!
pd.options.display.float_format = '{:,.2f}'.format이렇게 포멧을 변경해줍니다. 이러면,
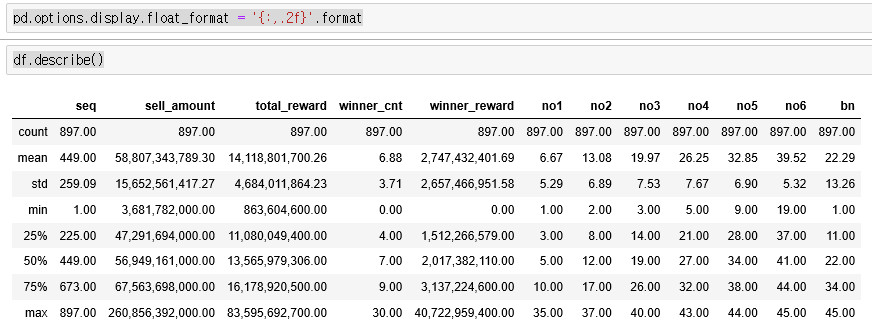
이렇게 보기 좋은 그림으로 숫자들이 표시되고 있는것을 확인 할 수있습니다.
여기서 확인 할 수있는건 평균적인 1인당 1등 당첨금액이 약 27억원 정도 된다는것을 알 수 있습니다.
또한 한 회당 평균 약 7명(6.88명)이 1등에 당첨되고 있다는 사실도 알 수 있으며,
1인당 최고 1등 당첨금은 약 407억원임을 알 수 있습니다.
또한 총 판매금액이 가장 많은건 2,608억원이 였습니다.
왜 이렇게 이 회차에는 판매금이 큰걸까요?

2,608억원의 판매금이 나온 회차는 10회차 였는데요, 7,8,9회차에서 1등이 나오지 않으면서 이월되었던것을 확인 할 수 있습니다. 이월 되면서 사람들의 1등 당첨에 대한 기대감이 커졌던것으로 추측 할 수 있습니다.
총판매금액 추이에 대한 그래프를 한번 그려 보겠습니다.
df['sell_amount'].plot(figsize=(20,6))
plt.legend()
plt.show()
총 판매금액은 전반적으로 초반에 높았다가 시간이 갈수록 약간씩 올라가는 모습을 볼 수 있습니다.
다만 2002년 판매개시때 바짝 올라 갔으나, 2008년까진 약간 하락세를 보이는 것도 볼 수 있습니다.
1등당첨금총액에 대한 그래프도 그려 볼까요? 이번엔 빨간색으로..
df['total_reward'].plot(figsize=(20,6),color = 'red')
plt.legend()
plt.show()
위에서 확인한 총판매금액 의 추이와 비슷하다는 걸 알 수 있습니다.
아마 로또 당첨 확률은 항상 일정하다는걸 확인 할 수 있는 그래프라 생각 되어 집니다.
자, 다음은 로또 1등당첨번호별 빈도를 살펴 보겠습니다.
당첨번호는 no1,no2...no6에 저장 되어 있습니다.
우선, 이 번호들을 각각의 데이터 셋으로 저장해 보겠습니다.
df1=df[['no1']]
df2=df[['no2']]
df3=df[['no3']]
df4=df[['no4']]
df5=df[['no5']]
df6=df[['no6']]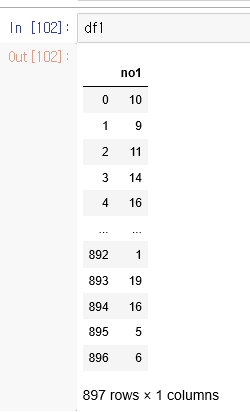
이런식으로 데이터가 저장 됩니다.
그럼 이걸 가지고 각각 데이터셋에 어떤번호가 몇번 나왔는지 group by count를 해줍니다.
df1_cnt=df1['no1'].value_counts()
df2_cnt=df2['no2'].value_counts()
df3_cnt=df3['no3'].value_counts()
df4_cnt=df4['no4'].value_counts()
df5_cnt=df5['no5'].value_counts()
df6_cnt=df6['no6'].value_counts()이렇게 df1을 가지고 df1_cnt를 만들어줍니다. 그렇게 6개의 데이터셋을 모두 처리 해줍니다.

이렇게 몇번 번호가 몇번 나왔는지 각 데이터 셋마다 저장이 되어 집니다.
이런 데이터셋이 6개 있겠죠? 그것들은 join해서 6개 데이터셋 모두를 합쳐 줍니다.
df1_cnt 와 df2_cnt를 join 해주고, 그 결과를 df3_cnt와 조인하면서 그렇게 6개를 다 join 해줍니다.
df_join2=pd.merge(df1_cnt_df,df2_cnt_df,left_index=True,right_index=True,how='outer')
df_join3=pd.merge(df_join2,df3_cnt_df,left_index=True,right_index=True,how='outer')
df_join4=pd.merge(df_join3,df4_cnt_df,left_index=True,right_index=True,how='outer')
df_join5=pd.merge(df_join4,df5_cnt_df,left_index=True,right_index=True,how='outer')
df_join6=pd.merge(df_join5,df6_cnt_df,left_index=True,right_index=True,how='outer')이렇게 DataFrame을 통해서 데이터 셋의 조인 하는 방법은 아래 블로그에 잘 나와 있으니 참고 하시기 바랍니다.
https://rfriend.tistory.com/259
[Python pandas] DataFrame을 index 기준으로 합치기 (merge, join on index)
지난번 포스팅에서는 Python pandas의 merge() 함수를 사용해서 Key를 기준으로 DataFrame을 합치는 방법을 소개하였습니다. 이번 포스팅에서는 pandas의 merge(), join() 함수를 사용해서 index를 기준으로 DataF..
rfriend.tistory.com
이렇게 데이터셋의 join이 끝나게 되면 아래와 같은 모습을 가진 데이터가 됩니다.
원래 join을 하게 되면 12.00 이런식으로 소숫점 뒤 두자리가 보이는데, 이걸 정수로만 표현하려면 아래 기능을 사용 하시면 됩니다.
pd.options.display.float_format = '{:,.0f}'.format그리고나서 값을 확인 해 보겠습니다.

이젠 여기에다가 cnt_sum 이라는 컬럼을 만들어서 각 숫자별 cnt를 합쳐주겠습니다.
우선 cnt_sum 이라는 함수를 하나 선언해 줍니다.
def cnt_sum(dt):
return (dt['no1']+dt['no2']+dt['no3']+dt['no4']+dt['no5']+dt['no6'])그리고 이 함수를 이용해서 cnt_sum에 값을 넣어 보겠습니다.
df_join6['cnt_sum'] = df_join6.fillna(0).apply(cnt_sum, axis=1)여기에서 fillna(0)을 호출한 이유는 위 데이터를 보시면 알겠지만 nan으로 된 빈값들이 있어서 해당 값을 0으로 치환 하겠다는 의미로 쓰입니다. 그래야 더해질수 있을테닌깐요.
그렇게 더해진 값이 cnt_sum에 update가 되었으니 확인 해 보겠습니다.

오우! 잘 저장된 것을 확인 할 수 있습니다.
그럼 이젠 각 로또 번호별 1등번호로 기출된 횟수를 찾았습니다.
기출 횟수로 정렬을 해서 보겠습니다.
df_join6.sort_values(by = 'cnt_sum', ascending = False)ascending을 False로 하여 desc 정렬이 되도록 합니다.

이렇게 보닌깐 34, 43, 27, 17, 40 번의 순으로 많이 나오고 있음을 알 수 있습니다.
그럼 1회당 어떤 번호가 당첨번호로 나올 확률도 구해 볼까요? rate라는 컬럼을 하나 더 만들어서 확률을 구해 넣어 보겠습니다.
def rate(dt):
return (dt['no1']+dt['no2']+dt['no3']+dt['no4']+dt['no5']+dt['no6'])/897*100
# rate 라는 함수를 만들고, 총 회차인 897로 나누고 100을 곱하여 줍니다.
df_join6['rate'] = df_join6.fillna(0).apply(rate, axis=1)
# rate라는 컬럼을 만들어 rate 함수의 결과를 update 합니다.
pd.options.display.float_format = '{:.2f}'.format
# 그리고 소숫점 두자리까지 볼 수 있도록 변경 합니다.
df_join6
# 데이터를 확인 합니다.
이 확률 데이터를 이요하여 그래프를 한번 그려볼께요.
df_join6['rate'].plot(figsize=(20,6),color = 'yellow')
plt.legend()
plt.show()
자, 이것으로... 이번 데이터 분석은 마쳐보겠습니다.
사실 이 방법 보다 더 간단한 방법이 있을꺼라고 전 확신 합니다만..
전, 아직 파린이닌깐요.... 여러 단계를 거치면서 데이터를 핸들링 하는 방법을 익혀본다고.. 스스로 위안을 삼아 봅니다.
많이 부족한 글 읽어 주셔서 감사드립니다.
혹시라도 좋은 방법이나 이 데이터로 할 수있는 다른 분석에 대한 아이디어가 있으시면 댓글로 공유 부탁드립니다!
오늘도 좋은 하루 되시길 바랍니다.
감사합니다.
by.sTricky